v6.0. Обновление кластеризатора


Сразу 3 важных обновления добавили в нашу систему.
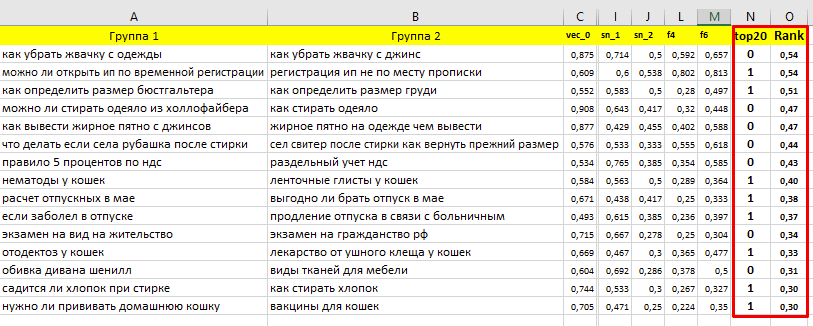
Модуль поиска каннибалов
Разработали новую систему, которая использует разные модели дистрибутивной семантики для поиска каннибалов.
На помощь кластеризации запросов по ТОПам для инфо тематик мы внедрили несколько вариантов формул расчета косинусного сходства (cosine similarity).
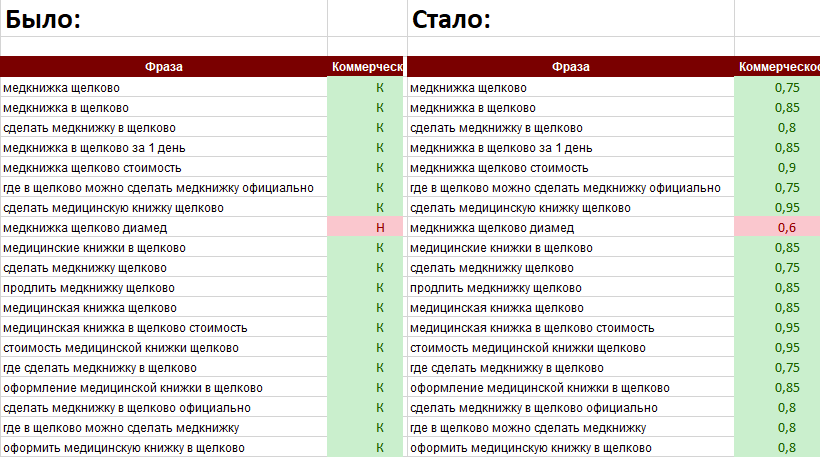
Коэф. коммерческости
Мы разработали модуль определения коммерческости по шкале от 0 до 1. Коэф. коммерческости – показывает долю присутствия коммерческих документов в ТОП10 Яндекса по запросу. Чем больше коэффициент стремится к единице, тем больше в выдаче по запросу коммерческих результатов. При расчете коммерческости мы учитываем 14 различных факторов из слов самого поискового запроса, сниппетов и документов ТОП10 выдачи.
0 — 0,35 – Информационный запрос.
0,36 — 0,6 – Запрос с неопределенным интентом документов.
0,61 — 1 – Коммерческий запрос.
Пример 1: Если «Коэф. коммерческости» =0 — это значит, что в ТОП10 все десять документов информационные и продвинуть коммерческую страницу будет сложно или нереально.
Пример 2: Если «Коэф. коммерческости» =0,5 — это значит, что спрос по запросу четко не определен и в ТОП10 присутствуют различные типы документов. Продвинуть можно страницу с любым контентом, который присутствует в выдаче.
Результаты работы нового модуля уже присутствуют во всех выгрузках наших семантических ядер:
Модуль «HandControl24» + отдел качества
Два месяца назад мы разработали новый модуль «HandControl24» и с его запуском все наши ядра в обязательном порядке проходят ручную проверку отдельным семантистом из отдела контроля качества семантики. Ручная проверка увеличила сроки работы над семантическим ядром на 2-3 рабочих дня, но значительно улучшила качество.
Семантист в модуле «HandControl24» зрительно проверяет каждую группу из семантического ядра и исправляет возможные недочеты, которые невозможно было определить в полуавтоматическом режиме. Различные параметры и подсветки позволяют семантисту быстро найти в группе возможные «залеты». В данном модуле, для анализа используется очень много данных: слова из самих ключей, модели дистрибутивной семантики, пересечение ТОПов и т.д.

Главные цели:
- найти «залетные» фразы в группе и удалить их или перенести в более подходящую группу (актуально для всех тематик).
- объединить группы запросов с похожим интентом (актуально для инфо тематик).
- разъединить группу на более мелкие, если у этих подгрупп разный интент или это разные товары (актуально для коммерческих тематик).
Дублирование контента и каннибализация ключей
Для максимального устранения каннибализации ключевых слов, дублей в различных статьях, а главное для экономии Вашего бюджета мы добавили в ТЗ копирайтеру пункт: «В статье просим не затрагивать следующие темы, так как они будут раскрыты в других статьях:»
Пример для статьи на тему: «как отмыть перепелиные яйца от пятен» пункт содержит следующие строки:
- мягкая скорлупа у перепелиных яиц что делать.
- как покрасить перепелиные яйца на пасху.
- можно ли пить сырые перепелиные яйца.
Важно: этот пункт очень полезен как для копирайтера, так и для владельца информационного ресурса, для понимания, какие еще статьи по теме есть в ядре.




