Гайд по работе с ТЗ копирайтеру от TaskБилдер


Приятно и наглядно.
Внешний вид ТЗ для копирайтера от TaskБилдер:
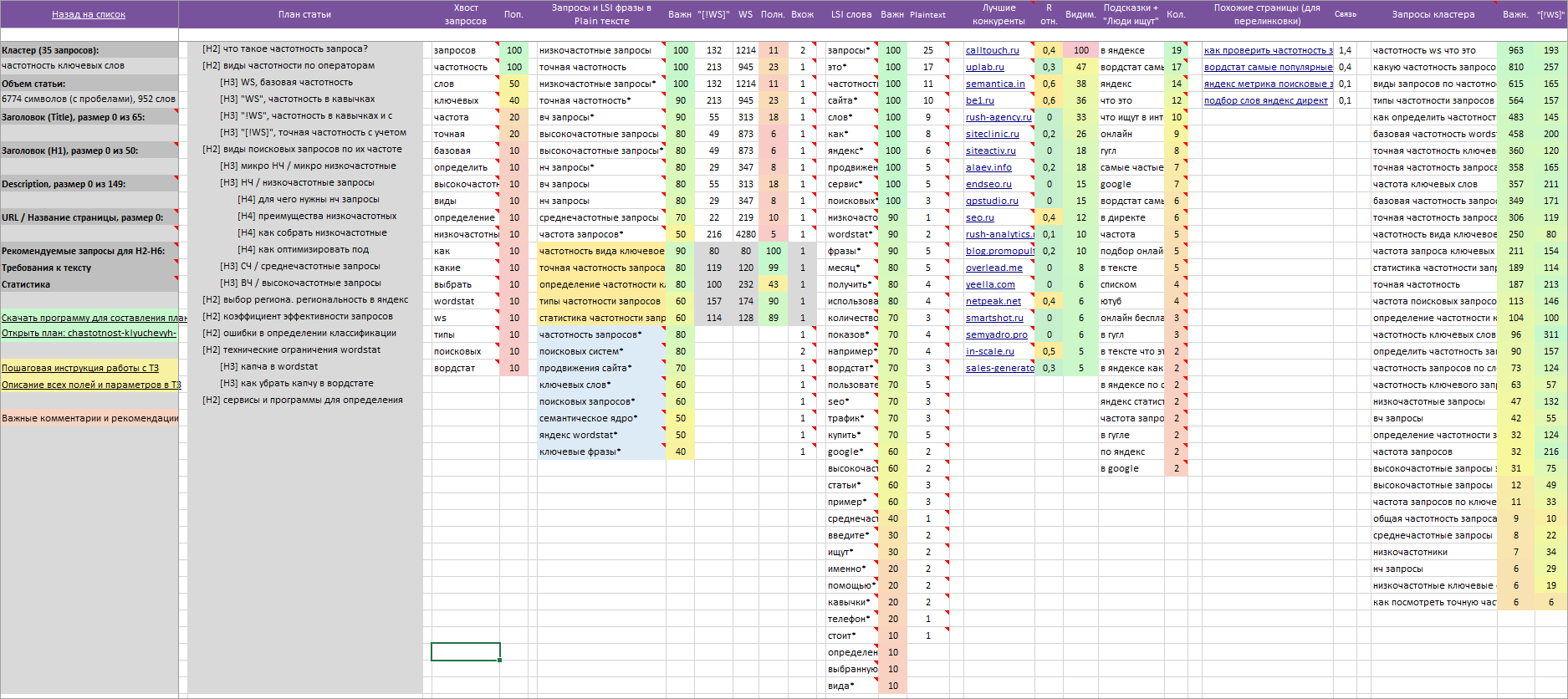
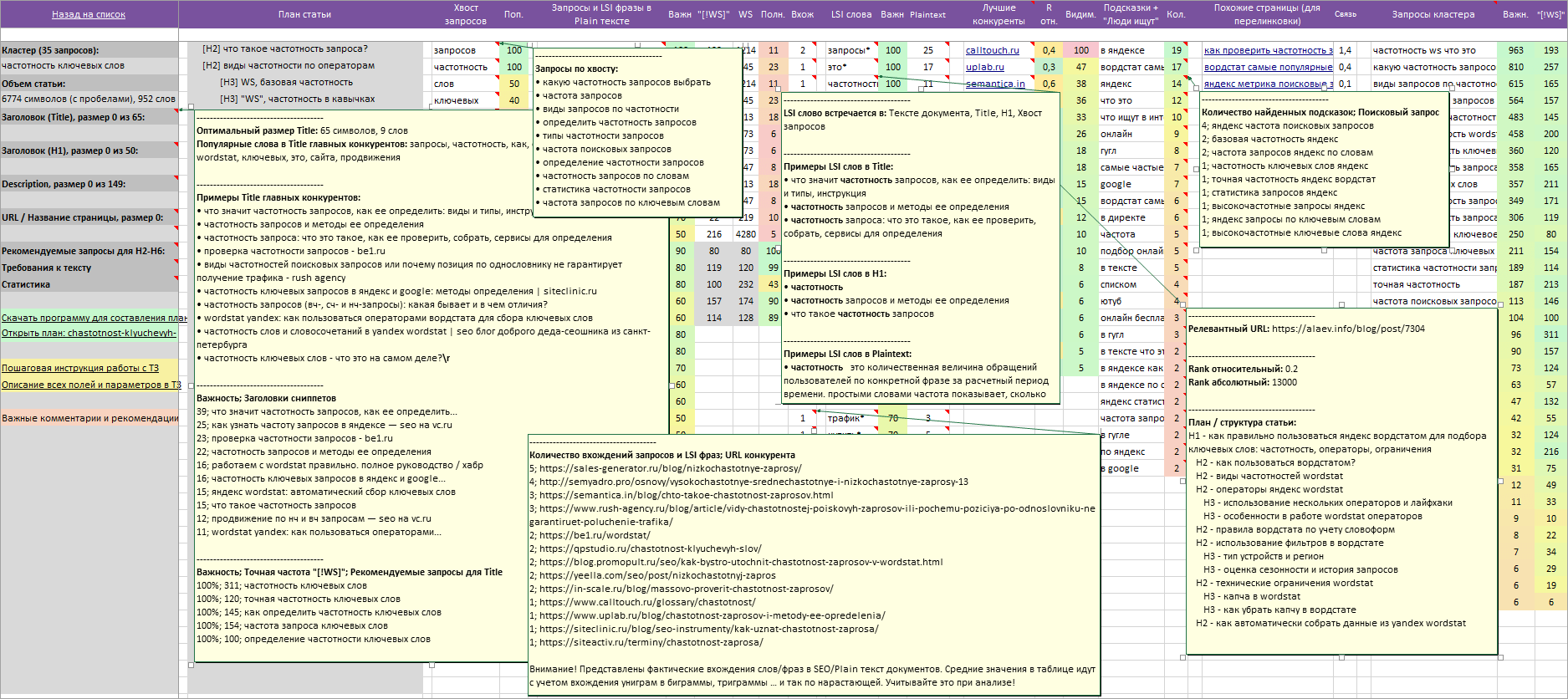
А такой шаблон уже с некоторыми всплывающими подсказками (все подсказки не реально уместить на одном скриншоте):
Статистика — наше все!
Перед началом работ надо понять:
- Какой размер кластера запросов и его общая частотность. Для небольших кластеров писать лонгрид не стоит. Если только эти запросы не «сверхприбыльны» для Вас и в ТОПе уже присутствуют лонгриды.
- Нужен ли текст вообще, а если нужен, то в каких объемах.
- Какое среднее количество заголовков H2-H6 используют конкуренты для раскрытия темы.
- Понять оптимальный размер Title, заголовка H1, дескрипшина.

Из примера выше, понятно, что статья «частотность ключевых слов» должна получиться средних размеров (7000-9000 символов) и для раскрытия темы в статье оптимально использовать 8-12 разделов/подразделов.
Если средний объем статьи у конкурентов до 300 символов и количество заголовков до 2 — тогда с большой долей вероятности seo-текст на странице не нужен (актуально для коммерческих запросов).
Если в колонке «Лучшие конкуренты» система смогла отобрать очень МАЛО подходящих конкурентов, это также сигнал, что seo-текст на странице не нужен, а нужны другие типы контента: листинг, таблицы, фото, формы заказа, калькуляторы …
Навигация
В любом деле важна правильная организация работы, быстрый поиск информации и удобная навигация между проектами.
Для увеличения скорости работы с Excel файлами в зависимости от размера проекта TaskБилдер может выгружать в одну книгу по 100, 200, 300 ТЗ копирайтеру и при этом будет работать сквозная перелинковка.
В каждой Excel книге первый лист идет под название «all» — это всегда общее для проекта меню со ссылками на отдельные технические задания.
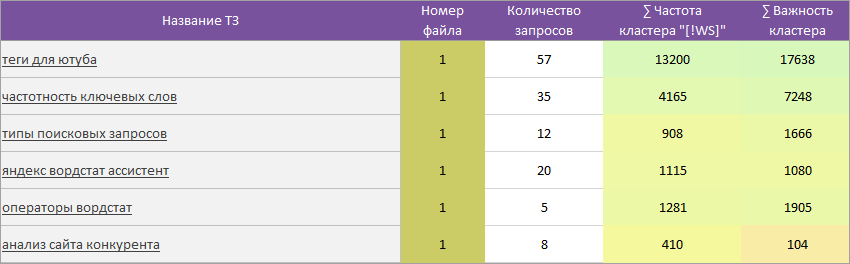
В нашей Excel-ной части ТЗ реализовано три варианта навигации:
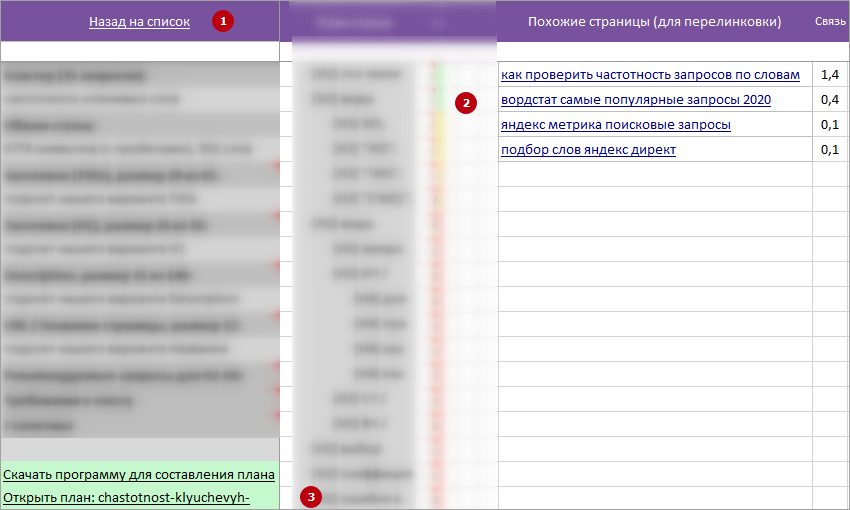
1 Ссылка на ячейке «A1» — «Назад на список». Быстро возвращает нас на 1 вкладку «all» с общим списком всех ТЗ на копирайт. Это позволяет быстро находить другие нужные нам ТЗ, искать похожие темы.
2 Колонка «Похожие страницы (для перелинковки)».
Позволят перелинковывать похожие статьи и не допускать каннибализации страниц.
3 Из Excel-ной части в Планмейкер.
Ссылка на ячейке «A20» (общий блок) ведет на проект в *.tskb формате.
Написание Title, H1, Description, названия документа
У некоторых компаний составлением заголовков, мета-тегов и названия документа занимаются seo-специалисты, а у некоторых эта работа делегируется ТЗмейкерам или копирайтерам на этапе написания статьи.
Я объясню, как использовать собранную информацию в нашем ТЗ, а Вы уж сами решайте кому с ней работать.
Для Title, H1, Description вынесено пять блоков подсказок и рекомендаций
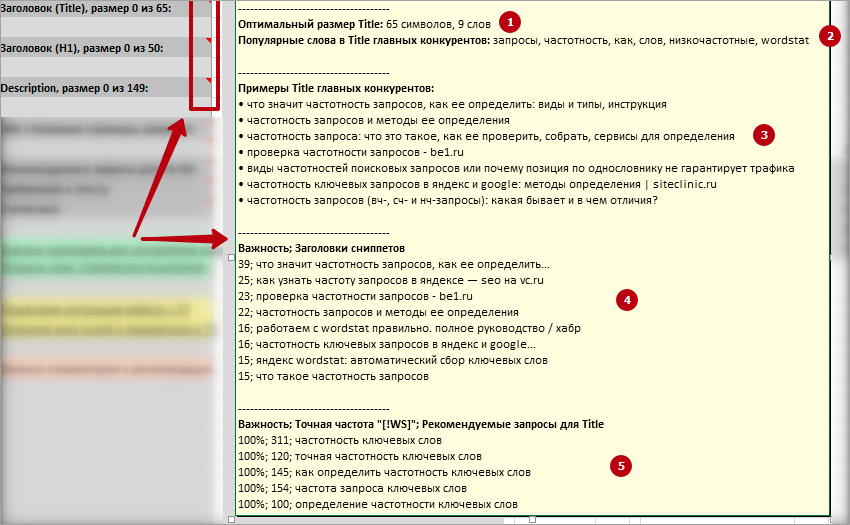
1 Оптимальный размер в символах и словах.
2 Список популярных слов конкурентов , отсортированных по падению встречаемости в соответствующих зонах документа.
* Например, для ячейки «Заголовок (Title)» — в представленном выше примере слова «запросы» и «частотность» чаще всего встречается в Тайтлах конкурентов.
3 Примеры содержимого соответствующих тегов самых близких конкурентов (колонка «Лучшие конкуренты»).
4 Примеры заголовков сниппетов , которые чаще всего выводятся по запросам кластера в выдаче + «Важность».
* Можно понять, какие слова и запросы самые значимые для поиска.
5 Рекомендуемые поисковые запросы + «Точная частота» + «Важность».
* Если важность у запроса одинаковая, обращаем внимание при выборе на частотность.
Приступать к составлению Title, H1, Description лучше в конце после изучения всего файла ТЗ и формирования плана статьи, когда уже станет понятно, что и как мы будем раскрывать в тексте.Рекомендуемый порядок работ:
1. Изучаем примеры написания конкурентами.
2. Изучаем сниппеты из поисковой выдачи.
3. Выбираем 1-2 главных запроса для внедрения в соответствующую зону документа из пятого блока подсказок или колонки «Запросы кластера».
4. Дополняем свой список словами из колонки «Хвост запросов».5. Формируем свой список.
Выбор правильного названия для документа

1 Популярные слова в названиях документов конкурентов.
2 Популярные названия документов + «Важность».
Составлен список популярных названий, у которых найдено больше всего слов из первого блока.
3 Список полных URLов главных конкурентов.
Три подхода к формированию названия:
1. «Долгий» — составить свой вариант из популярных слов и тематики статьи.
2. «Быстрый» — это взять самый подходящий по смыслу и важности вариант у конкурентов (2 блок) + дополнить словами из 1 блока И подправить его под себя.
3. «Транслит название кластера«. Используем, например, сервис advego и получаем для нашего примера, название: «chastotnost-klyuchevyh-slov».
* «Название кластера» — это ячейка «A4» в Excel файле.
Автоматический подсчет размера составленного варианта

- Первое значение на скриншоте выше — это размер нашего вписанного в ячейку ниже текста.
- Второе — рекомендуемый размер в символах (среднее по близким конкурентам).
Рекомендуемые запросы для заголовков H2-H6
- Как понять: использовать поисковые запросы в заголовках H2-H6 или нет?
- Сколько ключей оптимально прописать в H2-H6, чтобы не переспамить?
- Какие ключи из кластера приписать?
Советую обратить внимание на два блока данных в ТЗ копирайтеру:
1. Всплывающая подсказка в ячейке «A15» — «Рекомендуемые запросы для H2-H6».

1 Популярные слова в тегах H2-H6 конкурентов.
2 Рекомендуемые запросы H2-H6 на основе анализа близких конкурентов.
2. Подсказки на ячейках колонки «Лучшие конкуренты».
* Зрительно оцениваем структуру, вложенность заголовков и наличие ключевых слов у конкурентов.
Колонка «Хвост запросов»
Хвост запросов — это список популярных слов по всему кластеру запросов. Позволяет быстро понять о чем кластер, какие чаще всего слова встречаются в запросах, найти дополнительные темы для раскрытия в подзаголовках H1-H6.
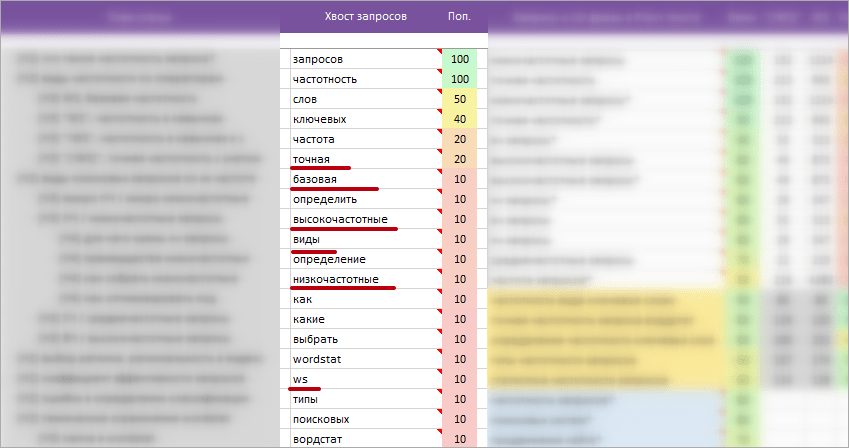
Рекомендую дополнять популярными словами из этой колонки Title, заголовки H1-H6 и текст для максимального раскрытия всего хвоста запросов на странице.
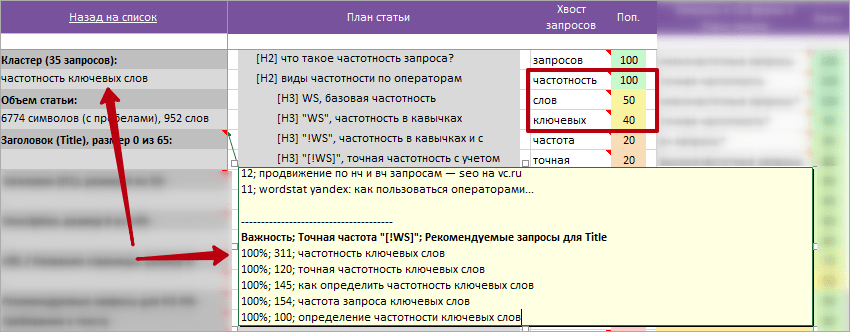
На примере выше видно, как Taskбилдер подобрал для максимального охвата вершины хвоста: «Название кластера» и «Варианты запросов для Title«.
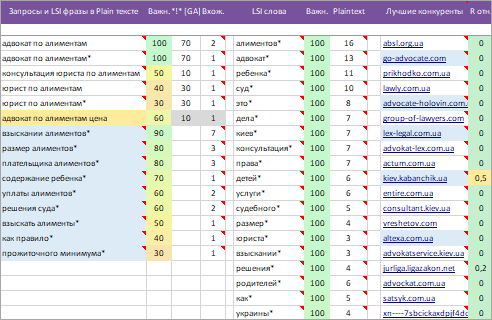
Колонка «Запросы и LSI фразы в Plain тексте»
В данную колонку, системой подобрано 3 блока запросов и LSI фраз для упоминания в «Plain/Seo/Основном» тексте страницы.
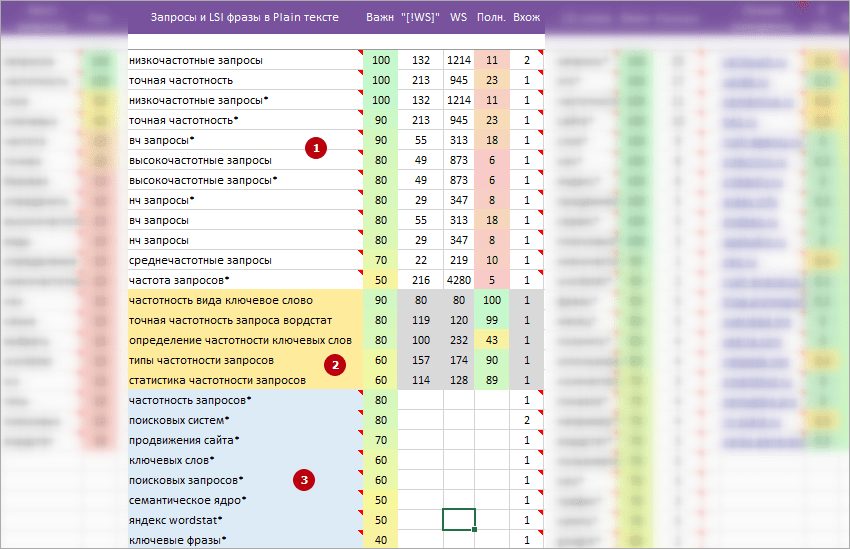
1 Первый блок (без фоновой заливки) — это запросы кластера, которые найдены на страницах конкурентов.
2 Второй блок (желтая заливка) — запросы не найдены у конкурентов, но содержат «уникальные слова» ИЛИ «популярные слова» из запросов, которых нет в 1 блоке и могут помочь в раскрытии темы. Если есть возможность TaskБилдер пытается отнять «Вхождения» у запросов первого блока (без фоновой заливки) для недопущения переспама.
3 Третий блок (голубая заливка) — это популярные LSI фразы + пропущенные на этапе сбора семантического ядра поисковые запросы кластера. Для пропущенных запросов, TaskБилдер также пытается отнять «Вхождения» у запросов первого блока (без заливки) для недопущения переспама. * Звездочка возле запроса или фразы говорит о том, что необходимо использовать «Не точное/Разбавленное» вхождение. Варианты написания выведены в подсказку.
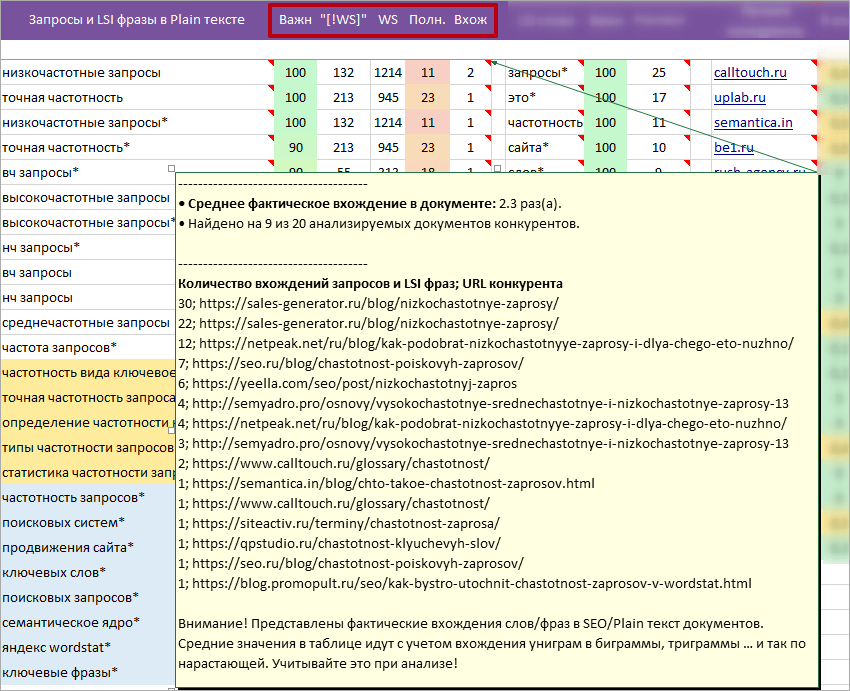
Связанные параметры
- Важн. — Важность поискового запроса, подробнее.
- [WS!] — Точная частота. Пример: «[!заказать !семантическое !ядро]».
- [WS] — Базовая частота поискового запроса.
- Полн. — Полнота или эффективность запроса. Рассчитывается, как отношение точной частоты к базовой и умноженное на 100 (Полн = [WS!] / [WS] * 100). Чем ближе значение к 100, тем более точно сформирован интент запроса. * При «Полноте» до 10% — запрос является слишком общим или многозначным, с малой долей целевого трафика. К таким относятся: «уборка», «продвижение», «Наполеон» и т.д. Такие фразы брать в продвижение оказывается нецелесообразно из-за повышенной конкуренции, малого «выхлопа» и сильного размытия интента пользователя. * При «Полноте» = 100% — запрос может быть искусственно накручен маркетологами, старательно вбивавшими его в поиск долгое время.
- Вхож. — Среднее (округленное) вхождение запроса или LSI фразы на документах близких конкурентов. * Среднее (фактическое) вхождение в документе можно посмотреть в подсказке при клике на ячейке.
Важно! Последовательность связанных параметров для колонок «Запросы и LSI фразы в Plain тексте» и «Запросы кластера» одинакова. Это позволяет быстро дополнять поисковыми запросами из колонки «Запросы кластера» в колонку «Запросы и LSI фразы в Plain тексте». Выделили, скопировали, вставили.
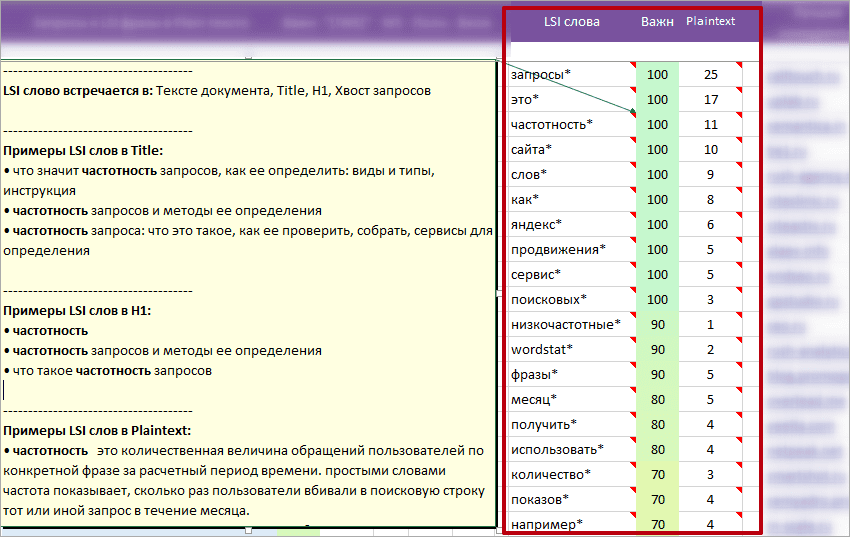
Колонка «LSI слова»
LSI ключевые слова — это слова, связанные с основным запросом семантически, по смыслу. Они позволяют сделать текст более естественным. Список LSI слов поможет копирайтерам сразу копать в нужном направлении, быстрее разобраться в незнакомой теме, учесть важные моменты.
* Например, для запроса «автосервис» будут подобраны LSI-ключи: ремонт, автомобиль, обслуживание, отзыв, работа, адрес, телефон, диагностика, двигатель.
Наша система TaskБилдер собирает и систематизирует LSI-ключи со следующих источников:
- Тайтлы (Title) документов.
- Заголовки H1.
- «Plain/Seo/Основной» текст страниц.
- Подсветка сниппетов поисковой выдачи.
Связанные параметры
- Колонка Важн. — Важность LSI слова.
- Колонка «Plaintext» — Среднее (округленное) вхождение LSI слова на документах конкурентов. Подсказка на ячейке поможет быстро проверить среднее количество вхождений и фактические вхождения по каждому конкуренту.
«Важность» — как рассчитывается?
При расчете важности для колонок «Запросы и LSI фразы в Plain тексте» и «LSI слова» учитывается:
- Количество вхождений в документы конкурентов.
- На каком количестве сайтов конкурентов найден запрос или слово.
- В каких зонах документа.
- Точная частотность и т.д.
Колонка «Лучшие конкуренты»
Очень важно при анализе учитывать только максимально близкие и похожие документы конкурентов. Большие сайты и агрегаторы в ТОПе могут быть совсем не из-за текстовой релевантности. А это грозит большими статистическими погрешностями и ошибками при выборе типа контента.
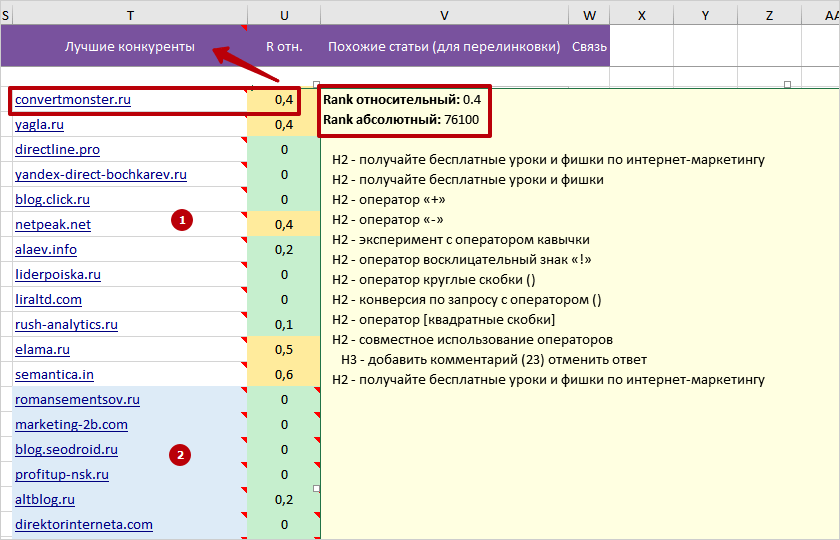
Эта колонка состоит из 2 блоков:
1 Первый блок (без фоновой заливки) — самые видимые в ТОПе и интересные в плане текста конкуренты, которые учитываются при всех расчетах параметров в ТЗ.
2 Второй блок (голубая заливка) — менее интересные конкуренты, которые не учитываются в расчетах, но могут использоваться при составлении плана статьи для лучшего раскрытия темы.
Первый и второй блок выгружается в файлы заданий в формате *.tskb для дальнейшей работы в Планмейкере по составлению плана статьи и подготовки текста на рерайт.
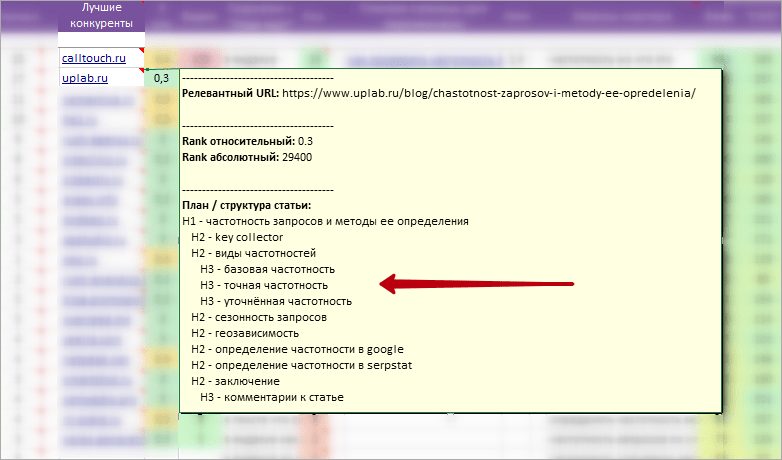
В примечания на ячейках колонки «Лучшие конкуренты» вынесено:
- Релевантный URL.
- Два коэффициента оценки авторитетности конкурентов: Rank Относительный и Абсолютный. Для примера: youtube.com (Rank домена абсолютный = 67100000000, Rank домена относительный =1), ru.wikipedia.org (Rank домена абсолютный = 19600000000, Rank домена относительный =1).
- Структуру статей, вложенность заголовков H2-H6.
Составление плана статьи
Анализируя планы статей конкурентов (вынесены в сплывающие примечания на доменах, колонка «Лучшие конкуренты») можно построить собственную структуру будущего текста.
Для этого удобно создать пустой Excel файл и копировать в него подходящие разделы и подразделы H2-H6 из примечаний.
Но, мы считаем, что более удобно это делать в нашей десктопной программе Планмейкер.
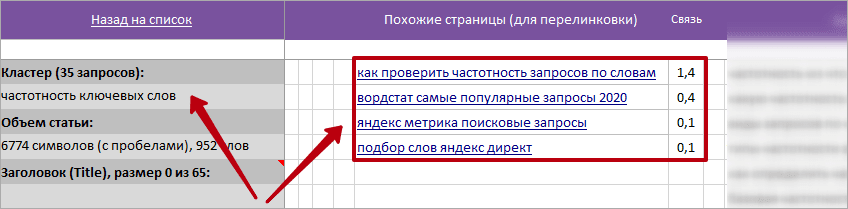
Колонка «Похожие статьи (для перелинковки)»
Каннибализация на сайте нам надо? Не надо! Тогда изучаем данную колонку и не допускаем создание дублирующего/похожего контента на сайте. Дополнительно рекомендую проверить первую вкладку «all» на наличие похожих страниц/статей.
Не забываем перелинковать похожие статьи/страницы и снова используем для этого данную колонку.
* При клике на названии статьи переходим на вкладку с этим ТЗ.
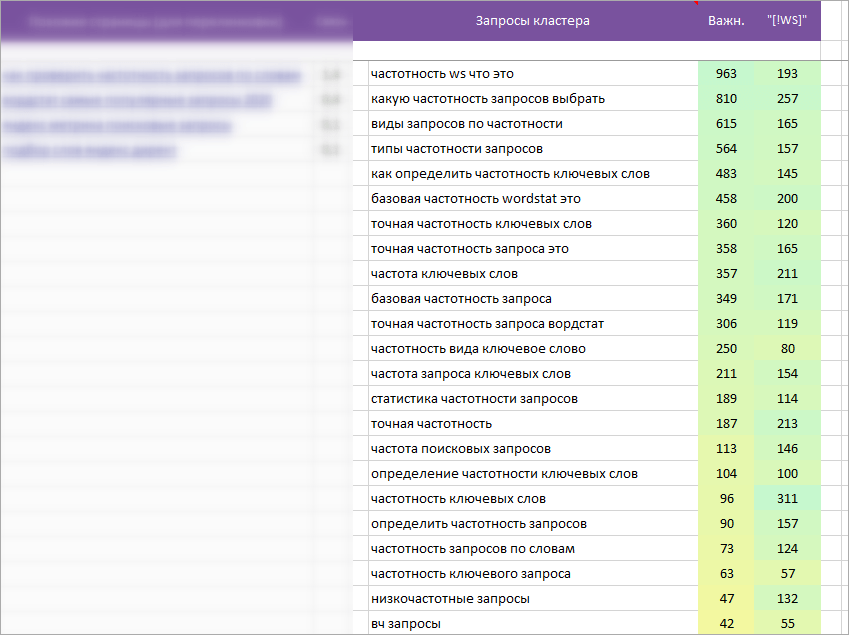
Ручной анализ группы запросов
- Если вы доверяете только своему опыту.
- Возникает вопрос: может TaskБилдер упустил важный запрос в рекомендациях на использование копирайтеру (колонка «Запросы и LSI фразы в Plain тексте«)?
У вас всегда есть возможность проанализировать кластер вручную. Колонка «Запросы кластера» содержит: полный список поисковых запросов кластера + «Важность» + «Точная частотность».
* Очень желательно после анализа данного блока удалять его из ТЗ, чтобы не путать копирайтера двумя списками поисковых запросов.
* Еще раз, главная колонка с запросами и LSI фразами для копирайтера — это «Запросы и LSI фразы в Plain тексте».
Экспресс порядок работы с тех. заданием
- Берем первое ТЗ в Excel формате.
- Копируем в отдельный файл, если надо отправить в работу только одно задание.
- Смотрит глазами подготовленные данные
* удаляем / добавляем информацию, если надо.
* если есть перегибы в значениях уменьшаем, не допускаем переспама.- При необходимости дополняем колонку «Запросы и LSI фразы в Plain тексте» вариантами из колонки «Запросы кластера». С последующим удалением данного блока из ТЗ.
- Открываем по ссылке связанный проект в «tskb» формате.
* в данном файле выгружены планы и тексты статей близких/видимых конкурентов.
* Гайд: как работать с Планмейкером?- Формируем максимально полный план статьи на основе планов конкурентов.
* перетаскиванием с левой части пункты в правую, если надо правим названия, если надо добавляем свои пункты.- Выгружаем готовый план из Планмейкера в html формат, копируем и вставляем его обратно в нашу Excel часть.
- Заполняем пустые ячейки тегов Title, H1, Description и название документа своими вариантами.
- После ручной правки, отдаем Excel копирайтеру.
- Получаем текст от копирайтера.
- Проверяем его на читаемость, раскрытие темы, «воду».
- Соответствие тех. требованиям и переспам проверяем в нашем текстовом анализаторе Семанайзер в личном кабинете.
- Внедряем готовый текст и мета теги на сайт.
Заключение
Если у вас возникли вопросы, предложения или вы нашли ошибки по техническому заданию для копирайтера от TaskБилдер — пишите в комментариях под этой статьей или в онлайн поддержку.



