Описание параметров в Excel части ТЗ копирайтеру от TaskБилдер


Подробный гайд по всем параметрам Excel-ной части ТЗ на копирайт от TaskБилдер. Обращайте ваше внимание на наши подсказки и рекомендации. Это значительно ускорит и упростит работу над нашим техническим заданием!
Внимание! Чтобы копирайтеры с различных бирж не пугались избытка данных и для экономии пространства, по умолчанию, первый и два последних блока данных — свернуты. Развернуть блоки можно кнопкой «+».
Начальный вид отчета соответствует «классическому» набору информации для ТЗ в текстовом формате:

1 Общий блок.
2 Блок запросов, LSI фраз и слов с важностью, рекомендуемым количеством вхождений и другими параметрами.
3 Изучаем и анализируем главных конкурентов, отсортированных по падению видимости.
Общий блок
Важно: Первая (общая) колонка в нашем ТЗ для копирайтера содержит: ячейки для формирования своих вариантов тегов Title, H1, description, названия документа + подсказки/рекомендации по их составлению + ссылки на: 1. Инструкции. 2. Программу Планмейкер. 3. Проект для составления плана в *.tskb формате.
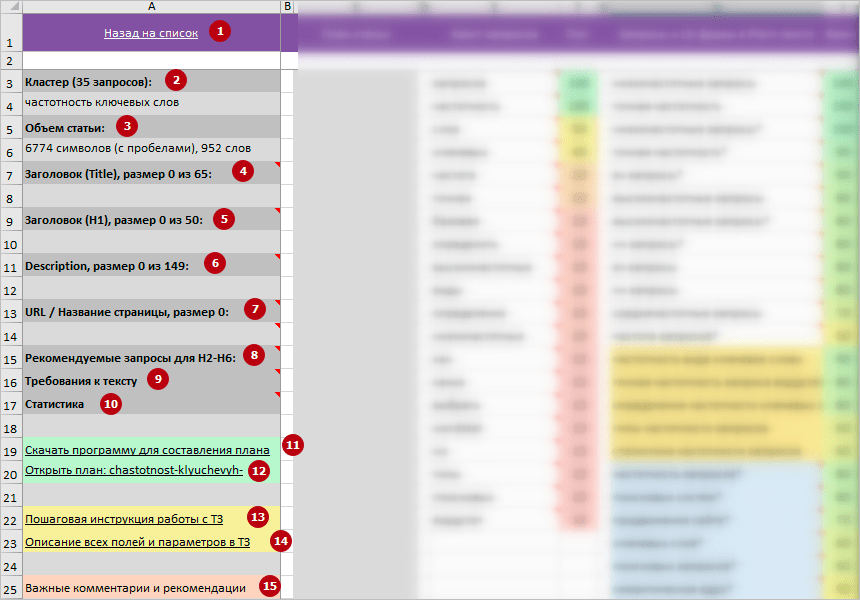
Описание полей на скриншоте выше:
1 Назад на список. При клике на ссылку идет переход с текущего ТЗ для копирайтера на первую вкладку «all» со всеми техническими заданиями.
2 Название кластера. Название кластера выбирается из самого частотного запроса в этом кластере.
* Кластер — это группа поисковых запросов, объединенная одним интентом (одной потребностью, желанием) пользователя и продвигаемая на одной странице.
* Очень часто название кластера соответствует главному запросу, который используется для формирования Title страницы / статьи.
Важно: Одно ТЗ копирайтеру формируется под один кластер из семантического ядра.
3 Объем статьи. Средний размер Plain / SEO текста самых видимых конкурентов (колонка»Главные конкуренты») по запросам кластера.
Объем рассчитывается в символах с учетом пробелов и в словах.
* Анализируются только Plain / SEO тексты конкурентов, а не весь документ.
4 Title. Тег в HTML, который задает заголовок документа. Часто используется в качестве заголовка в результатах выдачи, но не всегда.
Title играет важнейшую роль при seo оптимизации документа, так как участвует в расчете многих факторов ранжирования.
* На данной ячейке присутствует автоматический подсчет размера собственного варианта Title и среднего по конкурентам.
Пример: размер ХХ из ХХ (в символах).

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Оптимальный размер Title.
- Популярные слова в Title главных конкурентов.
- ТОП10 содержимого Title конкурентов.
- Самые популярные в выдаче заголовки сниппетов по кластеру запросов.
- Рекомендуемые запросы для Title.
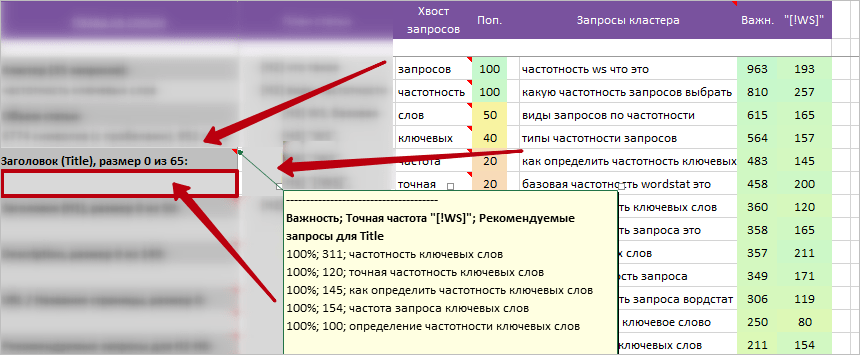
* Снизу в пустую ячейку, на основе подсказок в примечании, хвоста запросов и колонки «Подсказки + Люди ищут» вписываем собственный вариант Title.
* Формирование своего варианта Title. Рекомендуем следующую последовательность действий:
- Из колонки «Запросы кластера» или блока в подсказке «Рекомендуемые запросы для Title» выбираем 1-2 варианта главного ключа с максимальной «Важностью» или точной частотой «[!WS]».
- Верхушка слов из колонки «Хвост запросов» должна встречаться максимально в главном запросе.
- Финальный этап: дополняем + корректируем Title исходя из Title конкурентов, блока «Заголовки сниппетов» и колонки «Подсказки + Люди ищут».
* Такая последовательность позволит выбрать правильный вариант «главного поискового запроса» для Title и дополнить его важными / популярными словами по теме.
* Помним! Главный поисковый запрос должен быть: 1. Читаем 2. Вписан в пределах одного пассажа и максимально близко к началу.
5 Заголовок H1. Базовый заголовок первого уровня.
Второй по важности тег после Title при seo оптимизации документа.
* На данной ячейке присутствует автоматический подсчет размера собственного варианта H1 и среднего по конкурентам.
Пример: размер ХХ из ХХ (в символах).

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Оптимальный размер H1.
- Популярные слова в H1 главных конкурентов.
- ТОП10 содержимого H1 конкурентов.
- Рекомендуемые запросы для H1.
* Снизу в пустую ячейку вписываем собственный вариант заголовка H1.
* Формирование своего варианта H1. Рекомендуем следующую последовательность действий:
- Выбираем главный запрос из колонки «Запросы кластера» или блока в подсказке «Рекомендуемые запросы для H1»
- Учитываем колонку «Хвост запросов».
- Учитываем подсказки в примечании на ячейке.
* Это позволит выбрать правильный вариант «главного поискового запроса» для H1 и дополнить его важными / популярными словами по теме.
Важно: желательно, чтобы «главный поисковый запрос» и дополнительные слова между Title и H1 — отличались! Так можно охватить больше семантики на странице.
Пример: для Title берем главный запрос: «заказать семантическое ядро», для H1 немного менее частотный и важный запрос: «семантика для сайта на заказ»
6 Description. Мета описание — это тег, который сжато описывает содержимое страницы. Часто используется в качестве текста сниппета в результатах выдачи, но не всегда.
* На данной ячейке присутствует автоматический подсчет размера собственного варианта Description и среднего по конкурентам.
Пример: размер ХХ из ХХ (в символах).

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Оптимальный размер Description.
- ТОП10 содержимого тега Description конкурентов.
- Самые популярные в выдаче тексты сниппетов по кластеру запросов.
* Снизу в пустую ячейку вписываем собственный вариант заголовка мета Description.
* Формирование Description. Рекомендуем следующую последовательность действий:
- Выбрать 3-4 самых интересных предложения из Description конкурентов или текстов сниппетов.
- Из отобранных вариантов формируем свой вариант.
* Предложения берем у разных конкурентов, но они должны дополнять друг друга и коротко раскрывать содержимое нашей страницы.
7 URL / Название страницы. Название для страницы.
* На данной ячейке присутствует автоматический подсчет размера собственного названия страницы и средний по конкурентам. Пример: размер ХХ из ХХ (в символах).
* Формирование своего варианта URLа. Рекомендуем последовательность действий для формирования названия для нового документа:
- Из предлагаемых вариантов выбираем тот, в который больше всего входит слов из колонки «Хвост запросов».
- Снизу в пустую ячейку вписываем собственный вариант название документа для новой страницы или полный URL для существующей.
Пример 1: uborka-kvartit.html — для новой страницы.
Пример 2: https://наш_сайт/раздел/uborka-kvartit.thml — полный URL для уже существующей на сайте страницы.

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Популярные слова в URLах главных конкурентов.
- Предлагаемые примеры названий для нового документа.
- Полные URLы близких конкурентов.
8 Рекомендуемые запросы для H2-H6. Список запросов из кластера, которые найдены в точной, неточной или разбавленной форме на документах главных конкурентов.
Блок позволяет понять:
- Конкуренты используют поисковые запросы из кластера в заголовках H2-H6 или нет?
- Сколько запросов оптимально прописать в H2-H6, чтобы не переспамить?
* Чем больше вариантов запросов в списке, тем больше можно вписать у себя. - Какие запросы чаще всего используют конкуренты в заголовках H2-H6?
* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Популярные слова в H2-H6 главных конкурентов.
- Рекомендуемые запросы для H2-H6.
9 Требования к тексту. Краткий чек-лист для копирайтера, чтобы он быстро мог понять, какой должен быть текст в итоге, в какой стилистике писать.
Подкорректируйте всплывающее примечание на данной ячейке под ваши требования.
Вам нужно только оставить / дописать нужный вариант (ты) для следующих пунктов:
- Тип текста.
- Главная цель.
- Стилистика.
- Целевая аудитория.
10 Статистика. Во всплывающее примечание на ячейке вынесена сводка по средним размерам тегов конкурентов и статьи в целом + другая статистическая информация.
11 Скачать Планмейкер. Ссылка на скачивание актуальной версии десктопной программы по составлению плана / структуры статьи: Планмейкер от taskBilder.zip
* Программа и все обновления абсолютно бесплатны!
12 Открыть план. Ссылка на файл *.tskb с планами статей конкурентов.
Пример ссылки: /путь_к_папке_с_ТЗ/tskb/zakazat-semanticheskoe-yadro_3838621333.tskb
* Рекомендуем привязать по умолчанию формат *.tskb к программе TaskБилдер.exe (для автоматического открытия при клике на ячейке).
13 Пошаговая инструкция работы с ТЗ. Ссылка на статью «Пошаговая инструкция работы с ТЗ копирайтеру от TaskБилдер» в нашем блоге: перейти.
14 Описание всех полей и параметров в ТЗ. Ссылка на данную статью «Описание всех полей и параметров в ТЗ копирайтеру от TaskБилдер» в нашем блоге: перейти.
15 Важные комментарии и рекомендации. После анализа контента главных / близких конкурентов указываем рекомендации по созданию важных блоков в нашем контенте.
Пример: на странице обязательно реализовать голосование, сравнительную таблицу между товарами, квиз анкету, видео по теме, инфографику, цитаты и т.д.
План (структура) будущего текста статьи
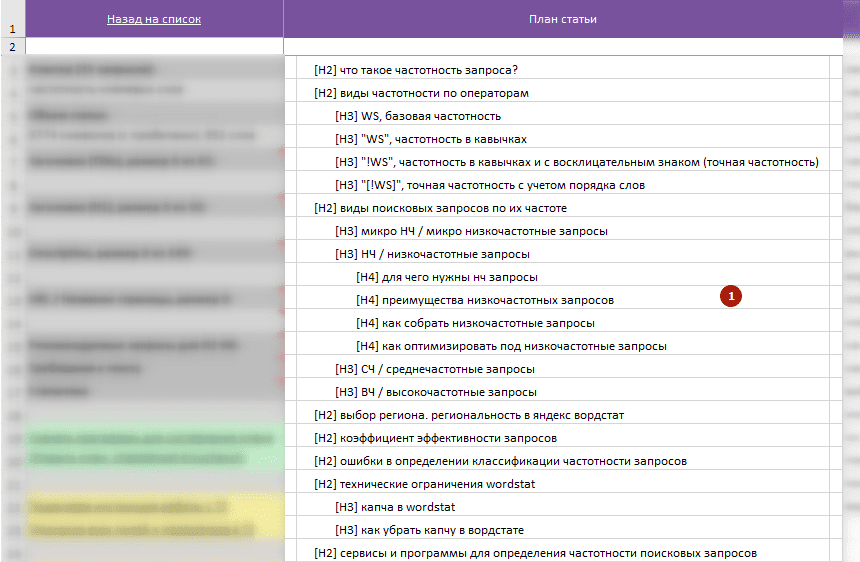
1 План статьи. Данная колонка предназначена для формирования плана будущего текста статьи. Изначально данная колонка пустая и ее необходимо заполнить своим планом. Формировать план можно 2 способами:
- Ручной. Анализируем всплывающие примечания на ячейках колонки «Главные конкуренты».
* В примечания вынесены заголовки H2-H6 соответствующих конкурентов. - Полуавтоматический. Формируем план статьи в нашей бесплатной программе TaskБилдер.exe используя подготовленный файл с планами в *.tskb формате.
* После составления плана в программе, экспортируем его в html файл, копируем и вставляем в колонку «План статьи».
* Полуавтоматический — более удобный и быстрый способ формирования плана будущей статьи!
Хвост поисковых запросов кластера
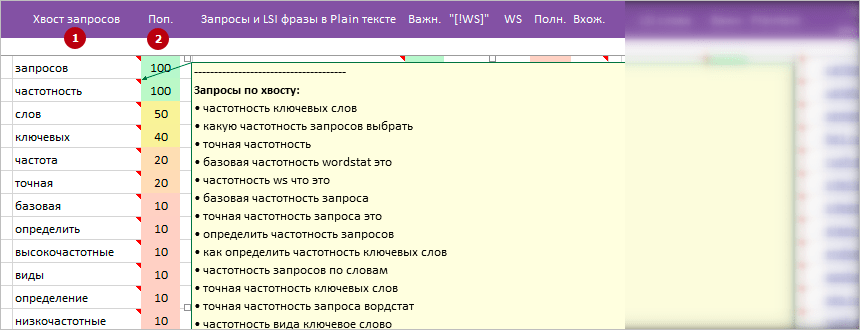
1 Хвост запросов. Изначально данный блок скрыт с экрана. Это список популярных слов по всему кластеру запросов.
Позволяет быстро понять, о чем кластер, какие чаще всего слова встречаются в запросах, найти дополнительные темы для раскрытия в заголовках H1-H6.
* Рекомендуем дополнять популярными словами из этой колонки наши варианты тегов Title, заголовки H1-H6 и текст для максимального охвата/раскрытия всего хвоста запросов.
* Примечание на ячейке. В примечание вынесен список запросов из кластера, где встречается слово.
2 Поп. Полное название параметра: «Популярность». Значение отображает, сколько раз в запросах кластера найдено данное слово.
Подсчет слов происходит с учетом морфологии.
Пример: слова «уборка», «уборке», «уборки» будут просуммированы и в ячейку записан самый популярный вариант слова в запросах.
Рекомендуемые запросы из кластера, LSI фразы и слова для текста статьи
Важно: Данный блок ускоряет поиск важных поисковых запросов из кластера, LSI фраз и слов в тексте для максимального раскрытия темы.
Блок можно свернуть / развернуть кнопкой +/- сверху над блоком.
* Удобно сворачивать, например, если для текущей работы нужен только блок «Похожие страницы и перелинковка». Лишние данные не будут отвлекать внимание на экране.
Списки формируются из 2 источников:
- Анализ Plain / SEO текста конкурентов (колонка «Главные конкуренты»).
- Поиск самых интересных запросов из кластера, которых нет на страницах конкурентов, но есть у нас в семантическом ядре. Они могут помочь более полно раскрыть тему статьи и привести дополнительный трафик.
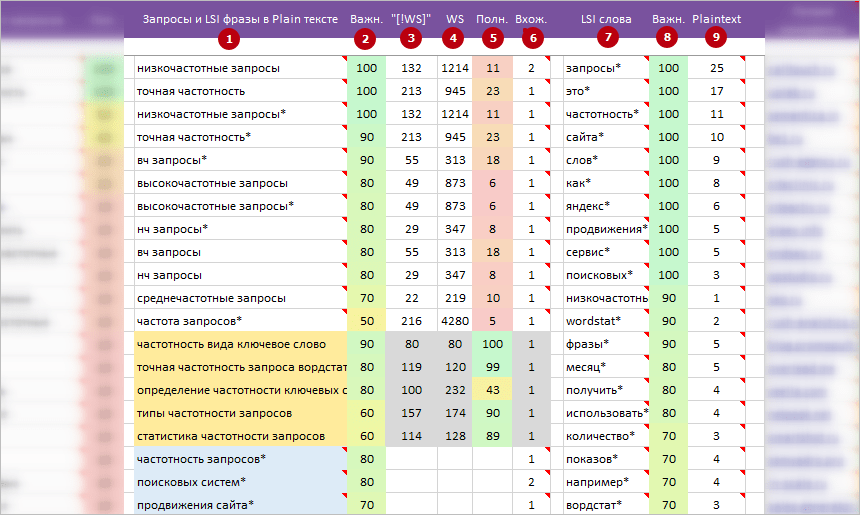
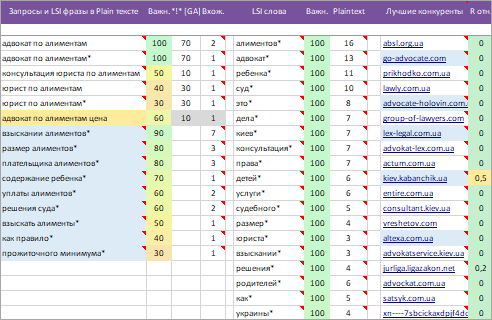
1 Запросы и LSI фразы в Plain тексте.
- Популярные запросы кластера — найдены в Plain / SEO тексте конкурентов.
* Запросы собраны в верхней части списка, в ячейках «без фона». - Дополнительные раскрывающие запросы. Запросы кластера — НЕ найдены в Plain / SEO тексте конкурентов.
Но, содержат «уникальные слова» ИЛИ «популярные слова» из запросов, которых нет в 1 блоке и могут помочь в раскрытии темы.
* Запросы собраны в ячейках на «желтом фоне».
* Если есть возможность TaskБилдер пытается отнять «Вхождения» у запросов первого блока (без фоновой заливки) для недопущения переспама. - Популярные LSI фразы — найдены в Plain / SEO тексте конкурентов.
LSI фразы собраны в конце списка, в ячейках на «голубом фоне».
* Внимание! В LSI фразы могут попадать популярные поисковые запросы, которые не нашли при сборе семантического ядра или случайно удалили на этапе чистки.
Важно: Точное и неточное вхождение. Если справа от запроса, LSI фразы стоит звездочка: * — это значит, что в тексте их используем ЕЩЕ и в не точной (морфология) / разбавленной форме.
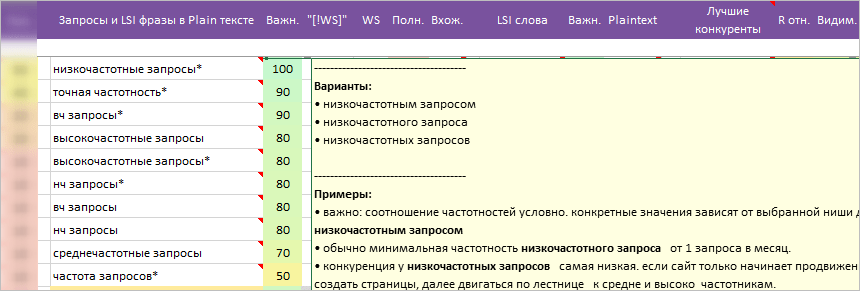
* Примечание на ячейке. В примечание вынесены части текстов с примерами написания запросов и LSI фраз на документах конкурентов + популярные варианты для запросов со звездочкой.
2 Важн. Полное название параметра: «Важность употребления запросов и LSI фраз в Plain / SEO тексте». Параметр изменяется от 0 до 100. Чем больше параметр, тем приоритетнее внедрение в тексте документа.
Как рассчитывается «Важность» для колонок «Запросы и LSI фразы в Plain тексте» и «LSI слова»?
При расчете важности учитываются следующие параметры:
1. Количество вхождений в документы конкурентов с учетом морфологии.
2. На каком количестве сайтов конкурентов найден запрос, фраза или слово.
3. В каких зонах документа найден запрос, фраза или слово (Title, H1-H6, тексте и т.д.).
4. Для запросов из кластера учитывается еще: точная частотность «[!WS]».
3 «[!WS]». Точная частота запроса по Яндекс Wordstat.
Именно точная частота (в кавычках «» + фиксация словоформы ! + фиксация порядка слов [ ] ) описывает ПОТЕНЦИАЛЬНО БЛИЗКИЙ поисковый трафик по ней.
Пример синтаксиса запроса к Яндекс Wordstat при анализе точной частоты: «[!уборка !квартир !москва]».
Данный синтаксис учитывает порядок слов в запросе и помогает оставить в ядре более частотную словоформу запроса.
4 WS / GA. Частота запроса по Яндекс Wordstat или среднее число запросов по Google Adwords в выбранном регионе (широкое соответствие).
Помните! Значение частоты запроса — это НЕ количество людей, искавших этот запрос. И даже НЕ то, сколько раз они нажимали в Яндексе / Google кнопочку «Найти».
Частота – это количество показов рекламных блоков Яндекс / Google по всем запросам, в который входит заданный поисковый запрос.
Пример: Базовая частота запроса «уборка квартир» = частотам «уборка квартир» + «уборка квартир в Москве» + «уборка квартир цены» + «заказать уборку квартир» + «уборка квартир спб» …
5 Полн.. Полное название параметра: «Полнота поискового запроса» или «Эффективность запроса». Параметр изменяется от 0 до 100.
Формула расчета параметра: Эффективность запроса = Точная частотность Яндекс Worstat / Базовая частотность Яндекс Worstat * 100.
Запросы с коэффициентом от 0 – 3 малоэффективны. Их при составлении ТЗ рекомендуется не использовать.
Запросы с низкой эффективностью / полнотой является слишком общим или многозначным, с малой долей целевого трафика. Пример: [уборка], [недвижимость] и т.д.
ИЛИ у запроса есть много близких словоформ, которые оттягивают на себя часть точной частоты.
6 Вхож.. Полное название параметра: «Среднее (округленное) количество вхождений в Plain / SEO тексты близких конкурентов».
Рекомендуется всегда проверять значения на «перегибы» и не допустить переспама в тексте по вхождениям (данные для проверки находятся во всплывающих примечаниях).

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Точная статистика вхождений без округления.
- Количество вхождений запросов и LSI фраз по конкурентам.
- URL анализируемого конкурента.
* Информация позволяет быстро проверить среднее количество вхождений и фактические вхождения по каждому конкуренту.
7 LSI слова. Это слова, связанные с основным запросом семантически, по смыслу. LSI слова позволяют сделать текст более естественным.
Список LSI слов поможет копирайтерам писать в нужном направлении, быстро понять незнакомую тему.
Пример: для запроса «автосервис» подобраны LSI-ключи: ремонт, автомобиль, обслуживание, отзыв, работа, адрес, телефон, диагностика, двигатель.
TaskБилдер собирает и систематизирует LSI-ключи со следующих источников: Title, H1, Plain / Seo текст страниц, подсветка сниппетов.

* Примечание на ячейке. В примечание вынесены части текстов с примерами написания данного слова у конкурентов + в каких зонах найдено данное слово.
Важно: Точное и неточное вхождение. Для LSI слов: * стоит на всех значениях (нет деления на точную, неточную и разбавленную форму) и в ячейку выводится самый популярный вариант этого слова у конкурентов.
8 Plaintext. Полное название параметра: «Среднее (округленное) количество вхождений слова в Plain / SEO тексты близких конкурентов».
Рекомендуется всегда проверять значения на «перегибы» и не допустить переспама в тексте по вхождениям.
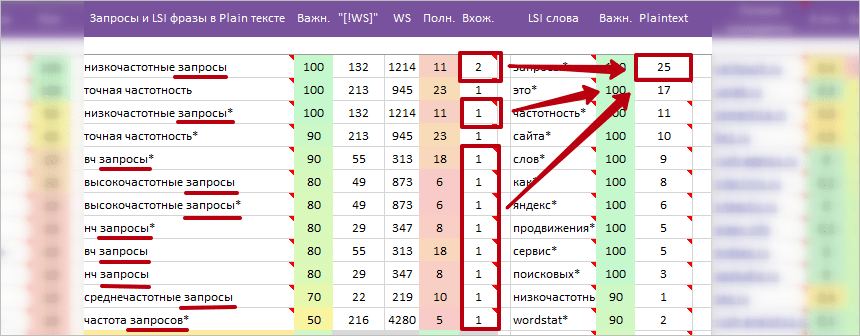
* Важно. Количество вхождений рассчитывается с учетом вхождения LSI слова в более длинные конструкции колонки «Запросы и LSI фразы в Plain тексте».
Пример: среднее число вхождения слова «запросы» по конкурентам = 36 раз, но это слово входит в более длинные конструкции: «низкочастотные запросы, высокочастотные запросы, вч запросы…» = 11 раз. Итого: в колонку «Plaintext» будет записано: 36-11=25 раз.
Аналогичные расчеты выполняются для запросов и LSI фраз.

* Примечание на ячейке. Всплывающее примечание на ячейке содержит следующие подсказки и рекомендации:
- Фактическое количество вхождений / встречаемость слов.
- URL анализируемого конкурента.
* Информация позволяет быстро проверить среднее количество вхождений и фактические вхождения по каждому конкуренту.
9 Важн. Полное название параметра: «Важность употребления LSI слов в Plain / SEO тексте».
Параметр изменяется от 0 до 100. Чем больше параметр, тем приоритетнее внедрение слова в тексте документа. Перейти на подробное описание: Как рассчитывается «Важность».
Список близких конкурентов
Важно: Блок позволяет проанализировать текст и контент в целом самых близких конкурентов.
Блок можно свернуть / развернуть кнопкой +/- сверху над блоком.
* Удобно сворачивать, например, если для текущей работы нужен другой блок. Лишние данные не будут отвлекать внимание на экране.
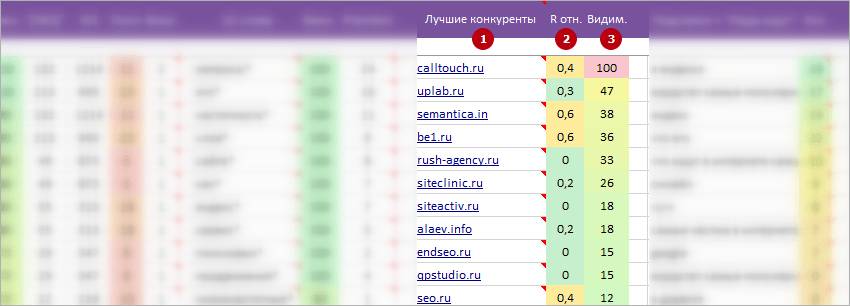
1 Главные конкуренты. ТОП доменов / URLов близких к нам конкурентов по всему кластеру запросов.
Вопрос: Почему выводятся домены, а не URLы?
Ответ: URLы слишком длинные, занимают много места на экране, их мы вынесли в примечания и в ссылки при клике на доменах.
При клике на домене в браузере открывается релевантный URL анализируемого домена.
Еще раз: Отображаются домены, но сортировка осуществляется по соответствующим URLам с учетом их видимости в ТОПе.
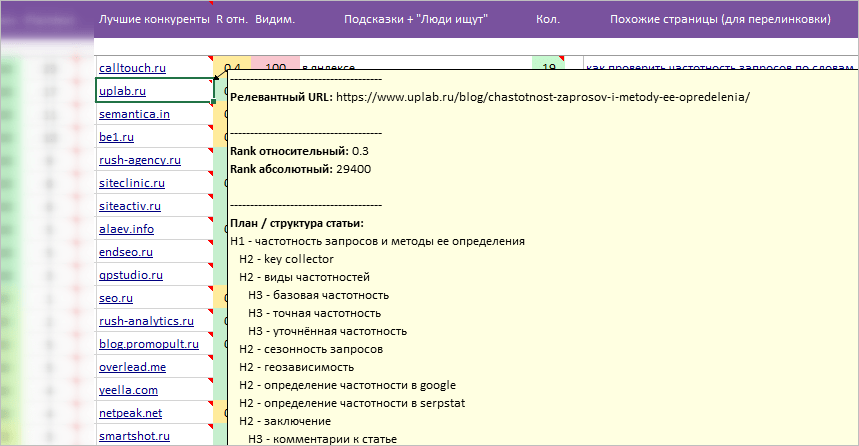
* Примечание на ячейке с доменом:
- Релевантный URL анализируемого домена.
- Параметры авторитетности домена.
- План / структура статьи на данном URLе.
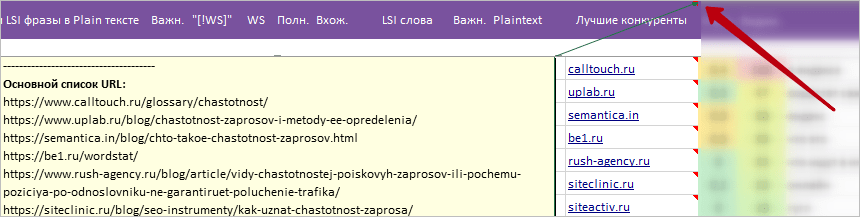
* Примечание на ячейке с названием колонки:
- Полный список URLов главных / близких конкурентов. Список можно использовать для анализа в сторонних сервисах.
2 R отн.. Полное название параметра: Rank домена относительный.
Rank домена относительный меняется в диапазоне от 0 до 1.
Значение 0 — сайт, которому принадлежит URL, это: молодой, небольшой, заброшенный или под фильтром сайт.
Значение 1 — сайт, которому принадлежит URL, это: сервисы поисковых систем, агрегаторы, большие магазины и порталы, пример: Яндекс.ru, youtube.com, vk.com, facebook.com, instagram.com, avito.ru и т.д.
Пример: Rank домена (относительный) для youtube.com = 1, его абсолютный Rank = 67100000000.
Чем больше Rank домена, тем сложнее обогнать данный URL в ТОПе.
Если у «Главных конкурентов» Rank от 0,4-1: надо хорошо поработать над планом статьи (максимально раскрыть тему) и наполнением. Конкуренция большая.
3 Видим.. Полное название параметра: «Видимость URLа»
Параметр показывает на сколько данный URL конкурента видим в ТОПе относительно других URLов этого кластера. Изменяется от 0 до 100.
Первый URL всегда самый видимый / важный по самым частотным запросам в кластере и чаще / выше других стоит в ТОПе.
При расчете коэффициента учитывается: частота запроса и позиция URLа в ТОПе.
Блок подсказок + «Люди ищут»
Важно: Блок позволяет расширить план статьи рекомендациями из подсказок.
1 Подсказки + «Люди ищут». Это популярные «поисковые подсказки» и подсказки в блоке «Люди ищут» по всем запросам кластера.
Данную колонку рекомендуем использовать для 2 целей:
- Для поиска похожих страниц на сайте для перелинковки. Анализируем вместе с колонкой «Похожие страницы (для перелинковки)».
- Для расширения текущей темы и формирование дополнительных заголовков H1-H6.
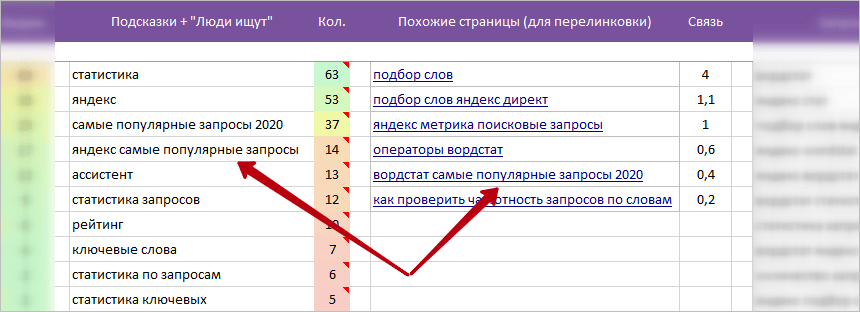
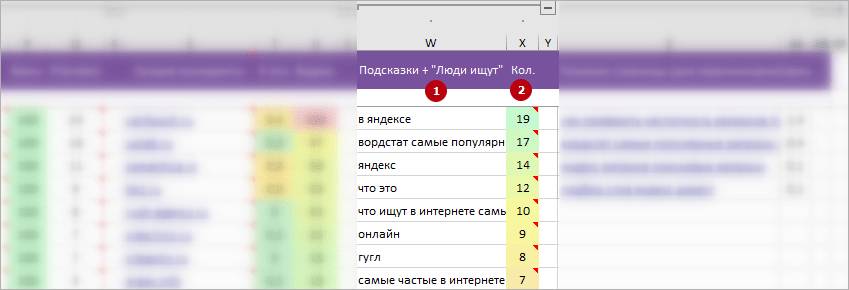
Пример для перелинковки (скрин выше):
- Работаем с ТЗ для копирайтера на тему: «как работать с вордстатом».
- В блоке подсказок на 3 позиции запрос: «самые популярные запросы 2020 яндекс».
* Полный вариант запроса можем посмотреть на примечании колонки «Кол.», это: «вордстат самые популярные запросы 2020». - У нас планируется отдельная статья на тему «вордстат самые популярные запросы 2020» — 5 позиция колонки «Похожие страницы».
- Возможное решение:
4.1. В статье сделать 1 абзац по самыми популярными запросами и далее перелинковать ее с главной статьей «вордстат самые популярные запросы 2020».
4.2. Перелинковать из текста и без создания отдельного абзаца.
Пример для расширения плана статьи текущего ТЗ (расширяем тему):
- Берем 5 позицию (скрин выше) из колонки подсказок, слово: «ассистент».
- Смотрим примечание на ячейке колонки «Кол.» с вариантами запросов.
>> Выбираем запрос: «яндекс вордстат ассистент». - В колонке «Похожие страницы» — нет отдельных статей на тему: «яндекс вордстат ассистент». Значит, раскрываем, как работать с вордстат ассистент в текущей статье.
* Важно: Дополнительно рекомендуем проверить, есть ли отдельная статья, через поиск по всем названиям статей на 1 вкладке: «all».
2 Кол.. Полное название параметра: «Количество»: абсолютное количество встречаемости слова / фразы в запросах из подсказок (популярность в подсказках).

* Примечание на ячейке. Собраны самые важные / популярные запросы из подсказок, где найдено это слово или фраза.
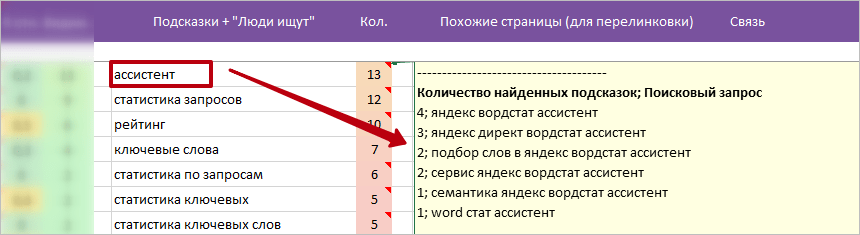
Пример: в колонке подсказок, слово: ассистент. Не совсем понятно, что это.
В примечании на ячейке «Кол.» первым в списке идет запрос: «яндекс вордстат ассистент». Совсем другое дело.
Похожие страницы и перелинковка
Важно: Данный блок рекомендуем использовать для выбора главной фразы при составлении: Title, H1 и проверки / дополнения блока «Запросы и LSI в тексте». Изначально данный блок скрыт с экрана.

1 Похожие страницы (для перелинковки). Список похожих страниц / статей для перелинковки и недопущения каннибализации на сайте.
* При клике на названии страницы / статьи переходим на вкладку с этим ТЗ.
Анализ похожих страниц / статей позволяет понять, какие темы мы вынесем в план текущего ТЗ, а какие раскроем на других страницах / статьях.
2 Связь. Уровень связи между текущей темой и другими страницами / статьями.
Чем больше значение, тем сильнее связь, тем больше общих URLов попадается в выдаче между запросами страниц / статей.
Запросы кластера. Полный список
Важно: Данный блок рекомендуем использовать для ручного выбора главной фразы при составлении: Title, H1 и проверки / дополнения блока «Запросы и LSI в тексте». Изначально данный блок скрыт с экрана.
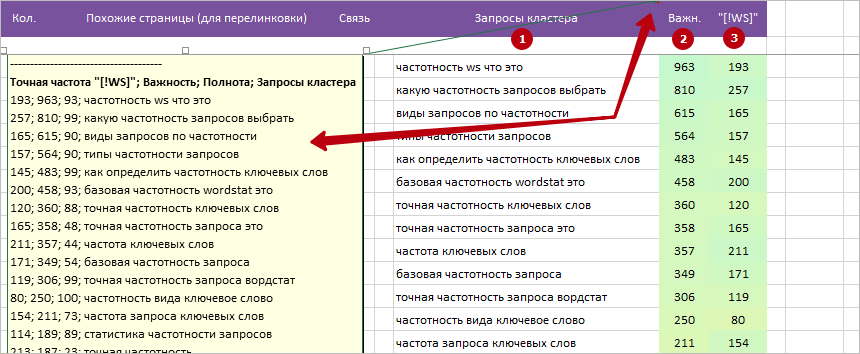
1 Запросы кластера. Это разные формулировки одной потребности / желания пользователей, которые они задают в поисковую систему.
Такие близкие поисковые запросы объединены в один кластер.
Помните! Потребность, которую задают люди по-разному через запросы — это РАЗНЫЕ люди, разный охват и спрос, которые не пересекаются, по которым разная конкуренция.
* В колонке видны только самые «Важные» запросы.
* Примечание на ячейке с названием колонки. Полный список запросов кластера можно найти на всплывающем примечании ячейки названия данной колонки.
2 Важн.. Полное название параметра: «Важность запроса в кластере».
При расчете учитываются следующие параметры: Точная частота «[!WS]» запроса + Полнота/Эффективность запроса + Rank домена (сложность ТОПа).
Чем больше значение важности, там приоритетнее запрос для использования в: Title, H1 и тексте страницы.
* У запросов с высоким приоритетом: высокая точная частота и полнота + низкая конкуренция в ТОПе.
3 «[!WS]». Точная частота запроса по Яндекс Wordstat.
Скачать описание полей и параметров в Excel формате
Если вам более удобно изучать материал в форме таблицы, мы подготовили вам данную инструкцию в Excel формате: скачать.



