v4.2. Очередное обновление кластеризатора семантики сайтов


Новые параметры в отчете
Добавлены новые столбцы в выгрузку СЯ:
1. Конкуренция [GA] — уровень конкуренции по версии Google Adwords:
0 — 0.33 — Низкая
0.33 — 0.66 — Средняя
0.67 — 1 — Высокая
2. CPC [GA] — Средняя стоимость клика по данным Google Adwords.
3. Оптимал. содержимое страницы — столбец для внесения данных по результатам анализа столбца «URL конкурентов». Результатом анализа должна быть информация о содержимом документов конкурентов. Пример: «листинг + текстовая информация + фильтр» или «текст + форма заказ+ прайс-лист» или «фотогалерея» и т.д.
Объявления конкурентов из Директа
4. Яндекс Директ — для каждой фразы из группы собраны объявления конкурентов в выдаче. Ячейка в столбце напротив каждой фразы содержит объявления в таком формате:
— Заголовок
— Текст объявления
— Домен
— Ссылка
Пример:
Сжигатель жира. Япония. 1675 р.
KWC Альфа-липоевая к-та и L-карнитин с вит.С,Е, В1,В2,В3, В6,В12. 120 табл.
www.kwc-japan.ru
http://bs.yandex.ru/count/MaVmkt…….

Информация очень полезная:
— при формировании собственных объявлений для контекстной рекламы;
— при создании текстов объявлений для рассылки на обычные доски объявлений;
— при формировании продающего title страницы.
Для удобного просмотра объявлений оптимально скопировать содержимого ячейки/ячеек в текстовый редактор.
Новый Топ урлов конкурентов
4. Полностью переработан поиск самых релевантных /видимых урлов/документов для группы фраз и соответственно расчет всех параметров для написания текстов. Раньше была простая формула поиска, а сейчас система учитывает частотность фразы в группе и позицию документа в ТОП 50.
5. Добавили новый столбец в файл выгрузки СЯ — «Коэф. авторитетности» — он показывает на сколько урл авторитетней относительно других урлов группы. Первый урл всегда 100% — он самый видимый/важный по самым частотным фразам в группе и чаще/выше других стоит в ТОПе.
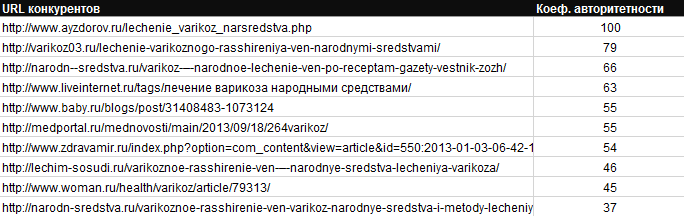
6. Плюс, сейчас рассчитывается не среднее значение, а медиана в задание копирайтеру, что не дает шумам вносить ошибки.
7. Добавили еще одну пост проверку правильности попадания фразы в группу — учет популярных слов в сниппетах из выдачи у каждой фразы.
Новые отчеты: top20url ,top20dom
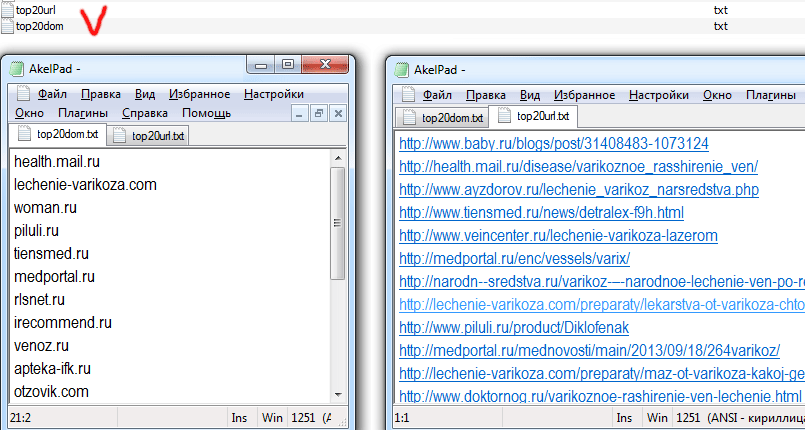
8. Плюс добавили 2 файла: top20url.txt ,top20dom.txt
Самые видимые документы и домены в СЯ с учетом 1 пункта.

Доработка системы кластеризации
9. Ведутся работы над увеличением возможностей системы группировать большие ядра, с 50 000 фраз до 200 000 фраз. Частично алгоритм уже внедрен в систему.
10. Доработан алгоритм группировки, исправлено ряд неточностей и небольших ошибок.
Новые параметры Яндекс Директ
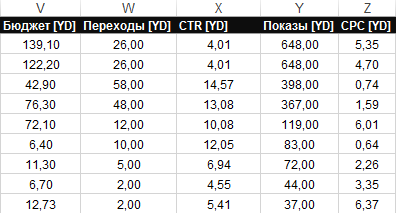
11. В файл СЯ выгружаются дополнительный блок параметров из Яндекс Директа:
- Бюджет [YD] — прогноз бюджета по ключевой фразе по данным Yandex.Direct.
- Переходы [YD] — количество переходов по ключевой фразе по данным Yandex.Direct.
- CTR [YD] — отношение числа кликов по ключевой фразе к числу показов по данным Yandex.Direct.
- Показы [YD] — количество показов ключевой фразы по данным Yandex.Direct.
- CPC [YD] — цена за клик по ключевой фразе по данным Yandex.Direct.
* Параметры будут полезны для организации контекстной рекламы.
Добавлены 2 новых столбца
12.1 «Использована в…» — в данный столбец напротив каждой фразы можно указывать где данная фраза использована.
Предлагаем следующие виды условных обозначений:
- txt — в тексте страницы
- title — в title страницы
- meta — в мета тегах
- img_alt — в альтах картинки
- A_out — во внешних ссылках
- A_in — в анкорах при внутренней перелинковке

12.2 «Журнал работ» — удобно вписывать что и когда сделано по данной группе фраз/странице, пример:
- 08.07.2014 Написаны title, keywords, description для страницы
- 05.07.2014 Прописаны alt у картинок на странице
- 02.07.2014 Закуплено ссылки с анкорами
- 01.07.2014 Заказан текст у копирайтера
Тз копирайтеру
13. Добавили выгрузку заданий копирайтеру в 2-х кодировках:
- windows-1251 — для пользователей windows
- utf-8 — для пользователей Мака

Файл статистики
14. Добавлен файл статистика результатов группировки, пример файла:
Всего групп: 158
Всего фраз: 1100
* Сгруппировалось: 1038
Новые модули в кластеризаторе
15. Разработан модуль по уменьшению очень больших групп фраз. Модуль позволяет после основных работ разбить большие группы на более мелкие, если это возможно. Разбивка возможна только если новые группы отвечают за свои более мелкие задачи/потребности пользователя.
16. Добавлена возможность автоматического объединения групп фраз, которые отвечают одним задачам/потребностям пользователя.

Но, самостоятельно собрать сложно.
Нет времени или опыта? Обращайтесь!

Новый столбик с названиями ячеек
Наш Title, Наш Keywords, Наш Description, Наш H1, Наш H2.
Под ними можно вбивать свои варианты этих тегов на основе анализа конкурентов, которые выгружаются сюда же.
Очень удобно держать их в одном файле и не искать каждый раз.
Правки шаблона ядра
18. Добавили 2 новых параметра:
- Топ-10 Yandex главной фразы;
- Топ-10 Google главной фразы.
В данные столбцы выгружаются ТОП 10 страниц выдачи по главной фразе. Отличие этих столбцов от «URL конкурентов» в том, что последний список формируется для всей группы запросов, а в предыдущие два только для главной/самой частотной фразы.
19. Так как количество столбцов в ядре за последние обновления сильно выросло, то для удобства работы добавили группировку столбцов (4 группы):
- от «Частотность» до «KEI -Конкур.»;
- от «URL конкурентов» до «H2-H6 конкурентов»;
- от «Наш …» до «Топ-10 Google главной фразы»;
- от «Кол.во символов (РЧТ)» до последнего столбца.
Группы можно раскрывать и скрывать, видимыми оставлять только те, с которыми работаете.

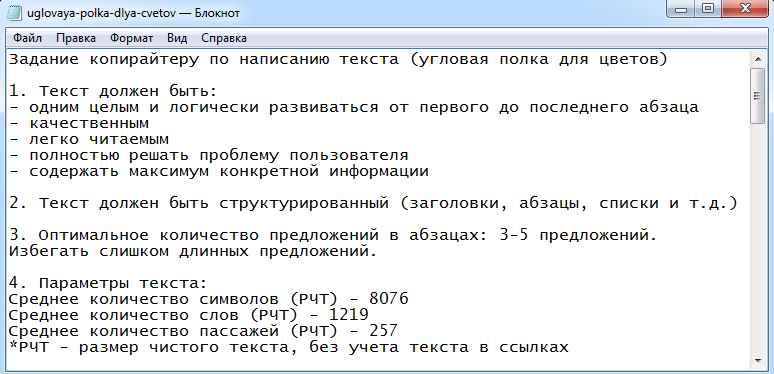
20. Добавили очень востребованный пункт: формирование задания для копирайтеров для каждой страницы/группы фраз. Система генерирует задание для копирайтера, подставляя в него соответственные значения из excel файла СЯ.
21. Добавили в ядро выгрузку релевантных страниц по Яндексу и Google для существующих сайтов, что значительно облегчит труд по подбору страниц.
- Релевантная страница Yandex
- Релевантная страница Google
- Релевантная страница

В третьем поле: «Релевантная страница » можно вносить свой вариант рел. урла. По умолчанию, если рел. урл по Яндексу и Google одинаковый, тогда в него система прописывает общий урл, если они разные - это поле остается пустым.
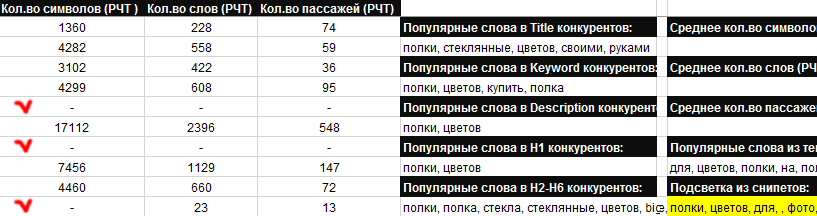
22. Добавлено ряд новых параметров в выгрузку ядра:
- Заголовок сниппета (с подсветкой важных слов)
- Сниппет (с подсветкой важных слов)
- Подсветка из сниппетов
Слова из подсветки также выгружаем в задание для копирайтера.

23. Для более точного расчета среднего количества символов, слов, пассажей убираем из обработки страницы, которые не загрузились или 404.
24. Разработана система предварительной чистки СЯ после сбора. После сбора со всех источников, мы обычно получаем список в 200 000 — 300 000 начальных фраз и с ними нужно что-то делать. Для облегчения труда операторов мы разработали систему, которая уже позволила нам в несколько раз ускорить процесс чистки.
.



