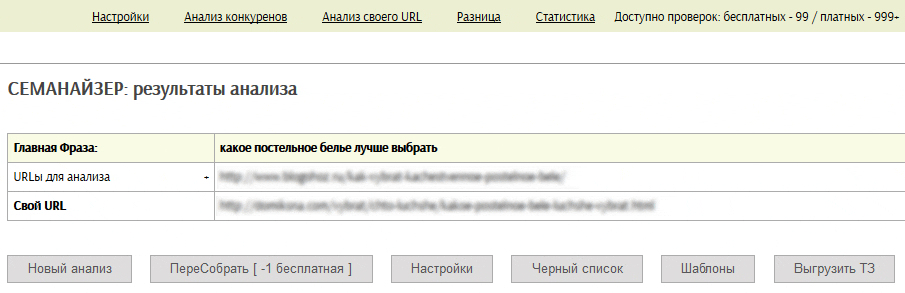
Семанайзер


Причины и история создания
Очень часто, когда пользователи сервиса Семен-Ядрен получали на руки семантическое ядро, спрашивали:
- А что дальше? Как правильно внедрять эту семантику на сайт?
- Какой контент формировать? Как не переспамить?
- Как сформировать ТЗ копирайтеру с конкретными цифрами?
Мы долго искали для них стороннее решение и постоянно сталкивались с проблемами, которые не позволяли дать единый инструмент для удобного и правильного решения поставленных вопросов.
Главные сложности:
- Инструменты решали отдельные задачи.
- Ограничения по количеству запросов на анализ или объем текста.
- Очень высокая стоимость анализа.
Все это не позволяло дать единый инструмент для удобного решения поставленных вопросов. И как результат, по истечению 4 месяцев разработок, мы выпустили инструмент «Семанайзер».
Помните: не главное вписать ВСЕ ключевые запросы и n-граммы в текст страницы из таблиц. Ваша задача — максимально раскрыть проблему посетителей.
Возможности Семанайзера
- Полученные данные позволяют оптимизировать страницы сайта без переспама и переоптимизации.
- Анализ контента конкурентов для составления ТЗ копирайтеру по собственному шаблону.
- Проверка соответствия собственного текста или текста от копирайтера до поставленного ТЗ.
- Поиск упущенных запросов, которые улучшат текстовую релевантность документа и принесут трафик.
- Поиск нежелательных / накрученных запросов, которые не нужно употреблять на странице.
- Быстрые подсказки: что нужно удалить/добавить без посещения конкурентов или своей страницы.
- Система за Вас проведет расчеты пересекаемости и вхождения одних запросов в другие. * Автоматическое вычитание необходимости упоминания коротких слов/фраз из более длинных. Пример: уборка квартир — уже используется в более длинном запросе — уборка квартир в Москве.

Преимущества
- Уникальный алгоритм деления содержимого страницы на SEO-текст и фрагменты.
- Полное устранение рутинных и ручных работ, все реализовано в одном инструменте.
- Больше 20 тегов и параметров для анализа.
- Около 80 переменных для построения собственного шаблона ТЗ копирайтеру.
- Множество настроек внешнего вида таблиц, параметров, порогов.
- Позволяет быстро и легко за один раз анализировать до 200 запросов в группе.
- Быстрый перерасчет данных в таблицах при изменении настроек.
- Доступна история проверок.
- Анализ по URLу документа или своему тексту.
- Наличие глобального и локального черного списка запросов и слов.
- Возможность расчета по средней или медиане всех параметров конкурентов.
- Анализируются: точное, разбавленное, морфологическое, морфологическое разбавленное вхождения. * Пример: уборка квартир, уборка небольших квартир, уборку квартиры, уборку небольшой квартиры.
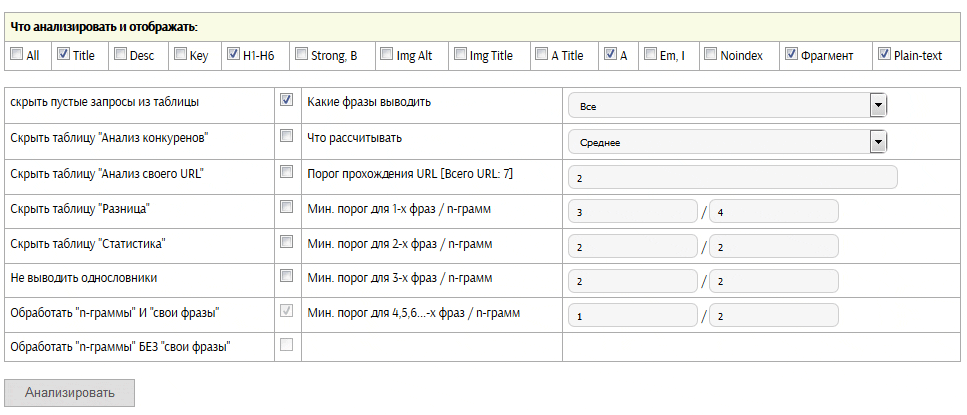
ТЗ копирайтеру
Тарифы
- Сбор и анализ до 150 запросов в группе: 0,9 руб.
- Пересбор до 150 запросов в группе: 0,5 руб.
- * Предоставляется 5 бесплатных проверок в сутки.
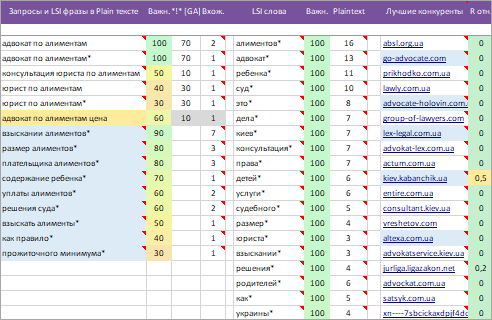
Параметры
Таблицы «Анализ конкурентов», «Анализ своего URL», «Разница»:
- All — часть документа заключенная в теге body.
- Title — содержимое тегов title.
- Desc — содержимое мета тегов Description, служит для краткого описания страницы.
- Key — в мета тегах Keywords содержаться ключевые слова и поисковые запросы документа.
- H1-H6 — содержимое тегов заголовков документа.
- Strong, B — содержимое тегов STRONG и B, браузеры отображают такой текст жирным начертанием.
- Img alt — содержимое атрибутов alt тега, устанавливает альтернативный текст для изображений.
- Img title — содержимое атрибутов title тега, текст показывается при наведении мышки на картинку.
- A title — содержимое атрибутов title тега A, текст показывается при наведении мышки на ссылку.
- A — содержимое текста ссылок (анкор).
- Em, I — одержимое тегов U, браузеры отображают такой текст курсивным начертанием.
- Noindex — часть документа заключенная в теге NOINDEX.
- Фрагмент — небольшие фрагменты текста.
- Plain-text — большие куски текста / seo текст.

Таблица «Статистика»:
- Title символов / Title слов — какой размер тега title в символах или словах у конкурентов.
- Description символов / Description слов — какой размер тега meta name=»description» в символах или словах у конкурентов.
- Keywords символов / Keywords слов — какой размер тега meta name=»keywords» в символах или словах у конкурентов.
- H1 символов / H1 слов — какой размер тег в символах или словах у конкурентов.
- Фрагмент символов / Фрагмент слов — общий размер текста во фрагментах у конкурентов.
- Plain-text символов / Фрагмент слов — общий размер seo текста у конкурентов.

Термины в инструменте
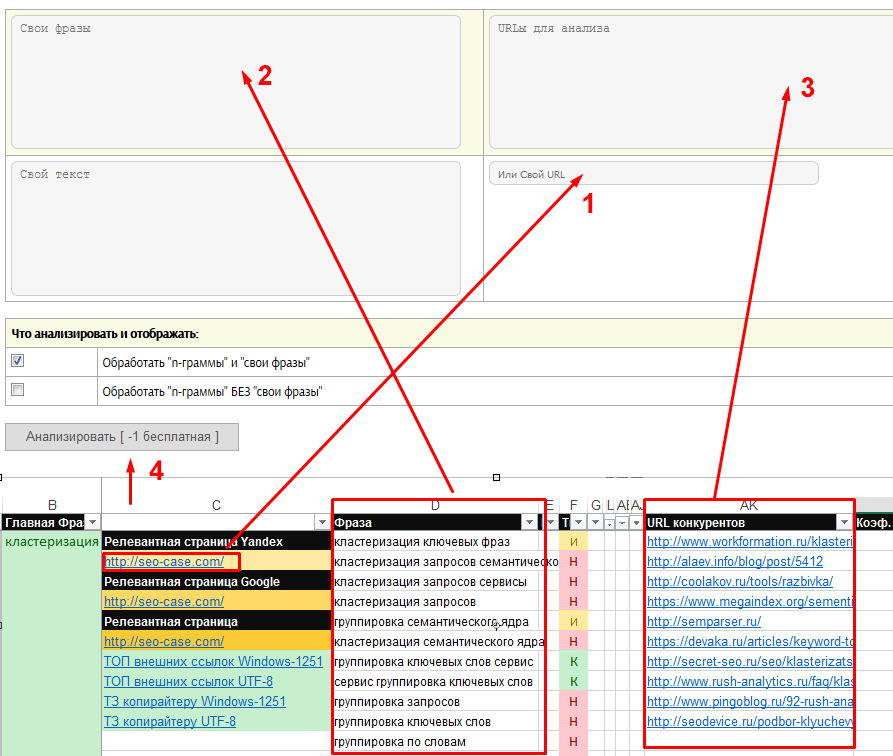
- Свои фразы — это запросы/слова, которые принадлежат одной группе и отвечают одному интенту / потребности пользователя.
- URLы для анализа — ТОП самых видимых документа по всей группе запросов.
- Свой текст — текст написанный Вами или копирайтером.
- Свой URL — адрес страницы, которую необходимо сверить с ТОП конкурентами.
- Обработать «n-граммы» И «свои фразы» — анализ своих фраз и популярных запросов/слов, которые часто используют конкуренты.
- Обработать «n-граммы» БЕЗ «свои фразы» — анализ только популярных запросов/слов, которые часто используют конкуренты.
- n-граммы — это популярные запросы/слова, которые часто используют конкуренты в тексте, но упущены у нас в «своих фразах».
- Главная Фраза — это первая фраза заданная в поле «Свои фразы». Первую фразу желательно задавать самую частотную в группе.
- Мин. порог для фраз / n-грамм — сколько минимально раз должна встретиться фраза / n-грамма на странице, чтобы попасть в таблицу.
- Порог прохождения URL [Всего URL:] — на каком количестве сайтов должна встречаться фраза/слово, чтобы попасть в таблицу.
- Скрыть пустые запросы из таблицы — показывать или не показывать в таблице «Свои фразы», которые не прошли пороги прохождения.
- Не выводить однословники — при включении опции в таблицах будут отображаться только фразы из 2 и более слов.
- Поле «№» — номер по порядку в поле «Свои фразы».
- Поле «Тип» — Н (n-грамма) / Ф (Свои фразы).
- Поле «Фраза / Домен» — анализируемая фраза или слово / количество доменов из поля «URLы для анализа», на котором они найдены.
- Поле «Black list» — «G-» — глобальный черный список, «L-» — локальный черный список для фраз и запросов.
Отличие от аналогов
С такими возможностями и гибкостью настроек аналогичные сервисы в свободном доступе не обнаружены.



