v4.6. Обновление кластеризатора запросов Семен Ядрен


Новые отчеты и параметры
Добавлена выгрузка ссылок на внешние документы для группы запросов / всего ядра
Добавлена выгрузка на внешние домены для группы запросов / всего ядра
для п. 4.1. и 4.2. в excel добавлены быстрые ссылки открытия соответствующих файлов.
Пример: для статьи о Key Collector будет очень полезно поставить внешние ссылки на сайты: seom.info и key-collector.ru
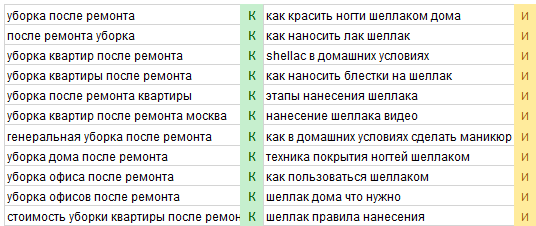
Добавлен параметр: «Коэф. внедрения» и группы отсортированы согласно этого коэффициента. Чем больше коэффициент, тем больше целевого трафика может принести группа фраз на сайт.
Ячейка «Главная Фраза» (название страницы) форматируется в цвета согласно типу страницы (инфо — желтый, коммерческий — зеленый, не определен — красный)
В excel файл добавлено 2 новых вкладки: «Структура» и «Описание полей».
- Вкладка «Структура» — вынесены все названия группы/страниц с раскраской ячеек соответственно до типа страницы. Удобно для построения визуальной структуры сайта.
- Вкладка «Описание полей» — описание всех параметров / столбцов главной таблицы семантического ядра с группами запросов.
В файл ядра вынесли ссылки на файлы ТЗ копирайтеру, что экономит массу времени на поиск нужного задания.
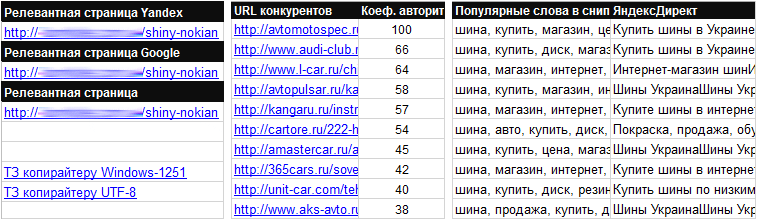
Добавлен новый столбец «Коэффициент авторитетности» — чем больше показатель, тем релевантнее документ к группе запросов
Добавлены в выгрузку 2 новых параметра: Конкуренция [GA], CPC [GA].
Добавлен столбец «Популярные слова в сниппетах», где собираются самые популярные слова из выдачи по каждому поисковому запросу в ядре.
Добавлена выгрузка объявлений конкурентов из Яндекс Директ по каждой фразе семантического ядра. Очень удобно использовать для написания собственных объявлений.
В выгрузку добавлен файл «white_dom.txt» — выгружаются по убыванию популярности самые тематические доноры. Оптимально использовать эти ресурсы для размещения любой возможной рекламы и получения трафика.
В выгрузку добавлен файл «all_snipet_1251.txt» — самые популярные слова из сниппетов по всему семантическому ядру. Удобно использовать для понимания тематического словаря и нахождения синонимов.
В выгрузку добавлен файл «all_fraz_1251.txt» — самые популярные слова из поисковых запросов по всему семантическому ядру. Удобно использовать для понимания тематического словаря и нахождения синонимов.
Для существующих сайтов выполняется выгрузка:
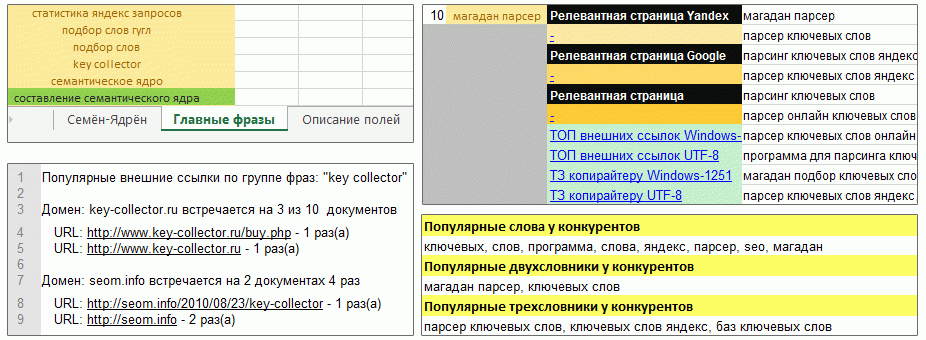
- Релевантных документов к группе запросов по версии поисковых систем Яндекс и Google.
- Выгрузка текущих значений для релевантного документа:

Доработка бесплатного ТЗ для копирайтера
Значительно улучшено формирование ТЗ копирайтеру.
Добавлена выгрузка популярных одно-, двух-, трехсловных фраз в текстах документов самых видимых конкурентов: «Популярные слова у конкурентов», «Популярные двухсловники у конкурентов», «Популярные трехсловники у конкурентов».
Новые возможности кластеризатора
Сервис научился работать с ядрами любых размеров.
Для ядер от 50 000 фраз разработан модуль деления на тематические кластеры/разделы, что значительно облегчает постмодерацию и работу с таким большим ядром в целом.
Добавлено 3 новых автоматических пост проверки результатов группировки:
- Уменьшение больших групп за счет удаления наименее эффективных фраз.
- Удаление неполных/небольших групп, которые содержат до 3 запросов.
- Удаление нетематических групп фраз. В результате система ищет те группы фраз, которые по ряду признаков нетематические в общем семантическом ядре и удаляет их.
Эти пост проверки позволяют значительно экономить бюджет при росте качества финального ядра.
В сервис добавлена автоматическая перегенерация ядра после ручной модерации. Любое семантическое ядро, не зависимо от метода его формирования (автоматический, полуавтоматический, ручной), требует ручной постмодерации. Некоторые группы и фразы в группах могут удаляться, группы объединяться и разъединяться, фразы переноситься и т.д. После всех этих действий необходимо перегенерировать данные семантического ядра: релевантные документы, ТЗ копирайтеру, другие общие параметры для новых групп.
Тип запроса
Разработан и добавлен в выгрузку уникальный алгоритм определения типа запроса: коммерческий/информационный/не определен.